【pytorch笔记】nn.modules怎么用
nn.modules怎么用
【pytorch笔记】nn.modules怎么用
前言
- 使用教程来自小土堆pytorch教程
- 配置环境:torch2.0.1+cu118与对应torchaudio和torchvision
引入库
1
import torch.nn as nn
直观测试
实例代码01 - 官方代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# Base class for all neural network modules.
# Your models should also subclass this class.
class Model(nn.Module): # 必须继承 nn.module 这个父类
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 20, 5)
self.conv2 = nn.Conv2d(20, 20, 5)
# forward 函数
# 输入 input 用来输出 output
def forward(self, x):
x = F.relu(self.conv1(x))
return F.relu(self.conv2(x))
# input - conv1 - relu - conv2 - relu - output
# 输入 - 卷积 - 非线性 - 卷积 - 非线性 - 输出
必须继承
nn.module这个父类
- 其实没啥说的,实现一个简单的 +1 操作,不过有了
forward()办法后,直接用括号就可以,不用.forward()了
神经网络
神经网络 - 卷积层01
- 以 torch.nn.functional.conv2d 中的 conv2d - 二维卷积层 为例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
import torch.nn as nn
import torch.nn.functional as F
import torch
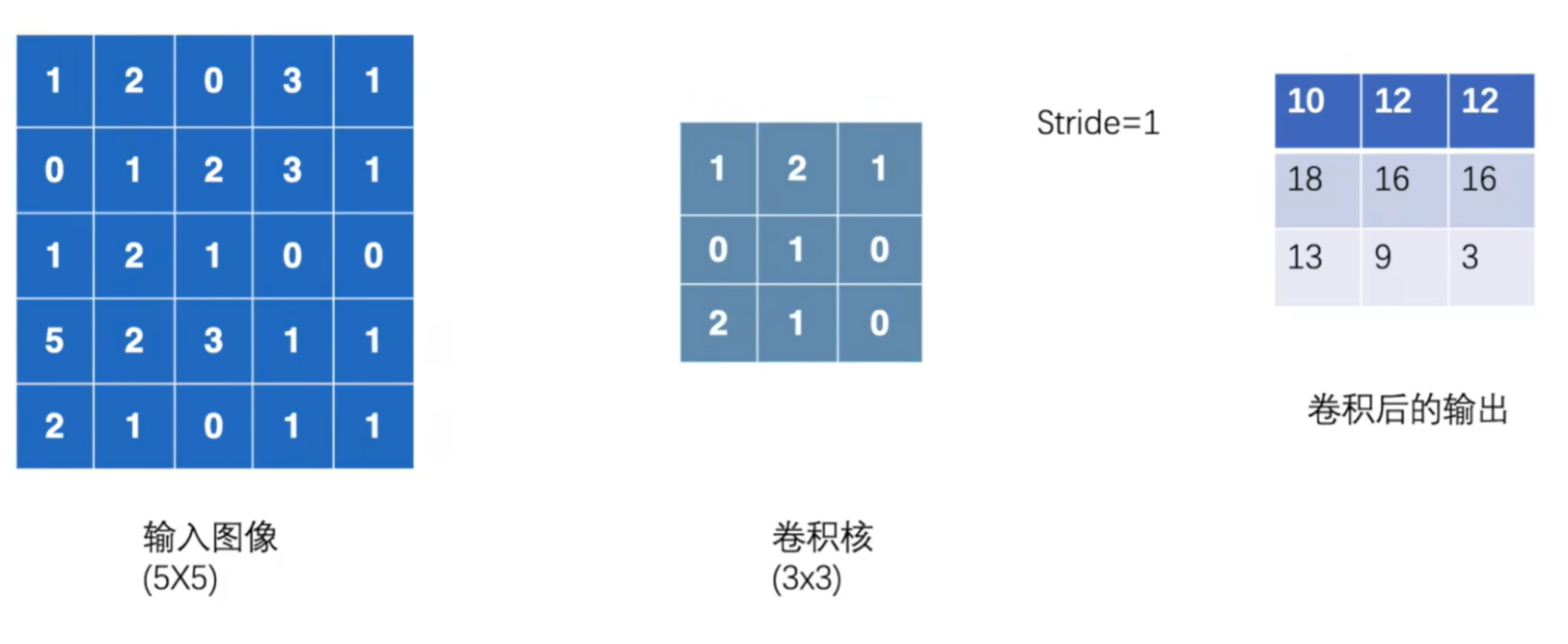
input = torch.tensor([[1, 2, 0, 3, 1],
[0, 1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]])
kernel = torch.tensor([[1, 2, 1],
[0, 1, 0],
[2, 1, 0]])
input = torch.reshape(input, (1, 1, 5, 5)) # 前两个1是 Batch Channel
kernel = torch.reshape(kernel, (1, 1, 3, -1))
output = F.conv2d(input, kernel, stride=1)
output2 = F.conv2d(input, kernel, stride=2)
output3 = F.conv2d(input, kernel, stride=1, padding=1)
'''
tensor([[[[10, 12, 12],
[18, 16, 16],
[13, 9, 3]]]])
tensor([[[[10, 12],
[13, 3]]]])
tensor([[[[ 1, 3, 4, 10, 8],
[ 5, 10, 12, 12, 6],
[ 7, 18, 16, 16, 8],
[11, 13, 9, 3, 4],
[14, 13, 9, 7, 4]]]])
'''
- input 输入tensor
- weight 输入 卷积核 kernel
- stride 就是步长
- padding 是否自动填充
dilation 元素间的步长
- 参考图片
神经网络 - 卷积层02
- 以
torch.nn.Conv2d这个类为例 kernel_size就是卷积窗口有多大
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
# 自定义类
class myModel(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(in_channels=3, out_channels=6,
kernel_size=3, stride=1,
padding=0)
def forward(self, input):
output = self.conv1(input)
return output
# 复习一下 Dataset Dataloader
dataset = torchvision.datasets.CIFAR10(root="tmp-tudui/CIFAR10", train=False,
transform=transforms.ToTensor(),
download=True)
dataloader = DataLoader(dataset, batch_size=64,
shuffle=False, num_workers=0)
# 创建对象
test_model = myModel()
step = 0
for data in dataloader:
img, label = data
print(img.shape) # torch.Size([64, 3, 32, 32])
output = test_model(img)
print(output.shape) # torch.Size([64, 6, 30, 30])
output = torch.reshape(output, (-1, 3, 30, 30))
print(output.shape) # torch.Size([128, 3, 30, 30])
step = step + 1
神经网络 - 最大池化
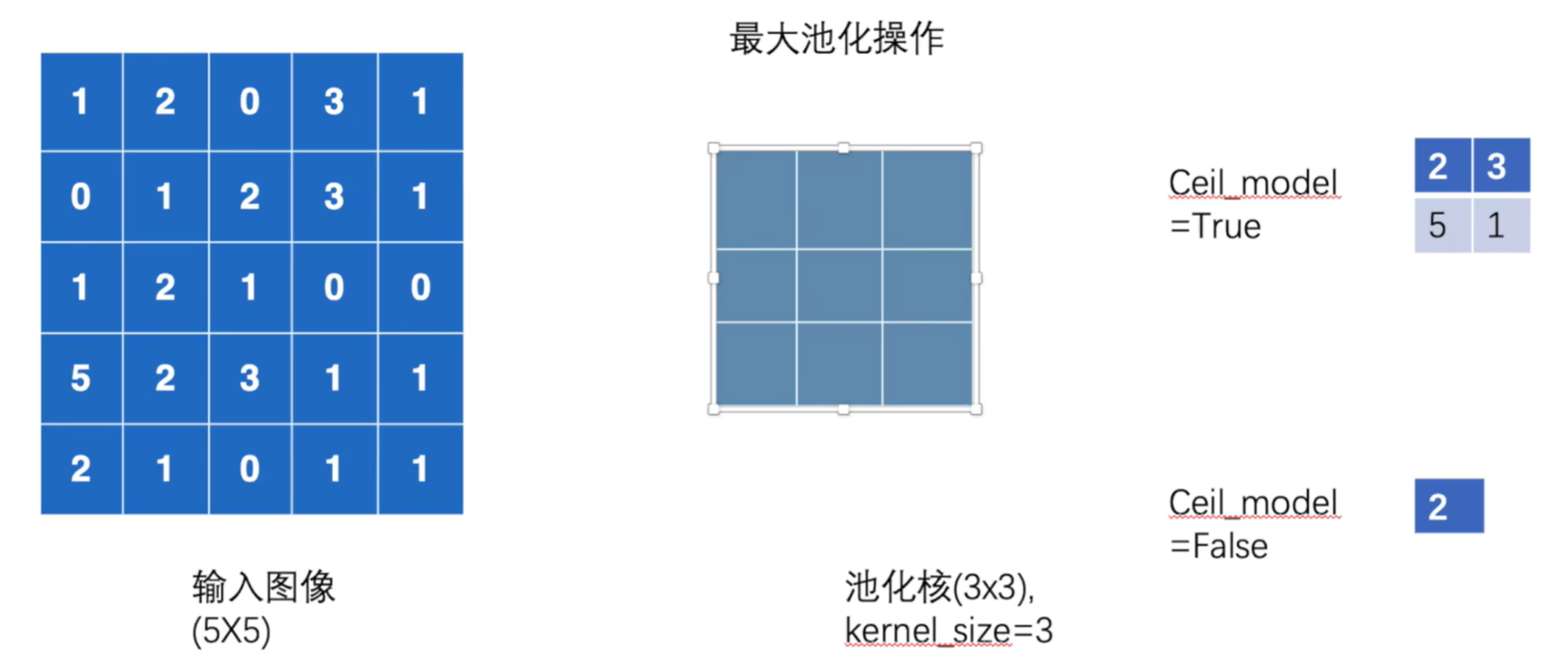
MaxPool也叫做“下采样” - 是减少数据点数量的过程,其目的通常是降低数据的分辨率或维度MaxUnpool也叫做“上采样” - 是增加数据点数量的过程,其主要目的是提高数据的分辨率ceil_mode是否对元素数量不够kernel_size数量的区域进行最大池化
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
class myModel(nn.Module):
def __init__(self):
super().__init__()
self.maxpool1 = nn.MaxPool2d(kernel_size=3, ceil_mode=True)
def forward(self, input):
output = self.maxpool1(input)
return output
input = torch.tensor([[1, 2, 0, 3, 1],
[0 ,1, 2, 3, 1],
[1, 2, 1, 0, 0],
[5, 2, 3, 1, 1],
[2, 1, 0, 1, 1]], dtype=torch.float32)
# 注意 输入进去的数据格式必须是浮点数
# 阅读文档可知
# input 格式要为 (N, C, H, W) 或者 (C, H, W)
input = input.reshape((1, 1, 5, -1))
test_maxpool = myModel()
output = test_maxpool(input)
- 输入进去的数据格式必须是浮点数
- input 格式要为 (N, C, H, W) 或者 (C, H, W)
最大池化的意义:在保障数据质量的情况下,减少数据参数
- 参考图片
神经网络 - 非线性激活
- inplace 默认False True的情况下替代 False的情况下返回一个新 tensor
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
input = torch.tensor([[1, -0.5],
[3, -1]])
input = torch.reshape(input, (1, 1, 2, 2))
class myModel(nn.Module):
def __init__(self):
super().__init__()
self.relu1 = nn.ReLU(inplace=False)
# 默认函数是 max(0, x)
self.sigmoid = nn.Sigmoid()
# 这边用一下经典的非线性激活函数 Sigmoid()
def forward(self, input):
output = self.sigmoid(input)
return output
model = myModel()
output = model(input)
神经网络 - 线性层及其它层介绍
- Recurrent Layers -> 主要用于字体识别
- Linear Layers -> 一般通过线性层: 直接看图,注意,参数中的
bias代表线性方程中的b要不要有,默认有的;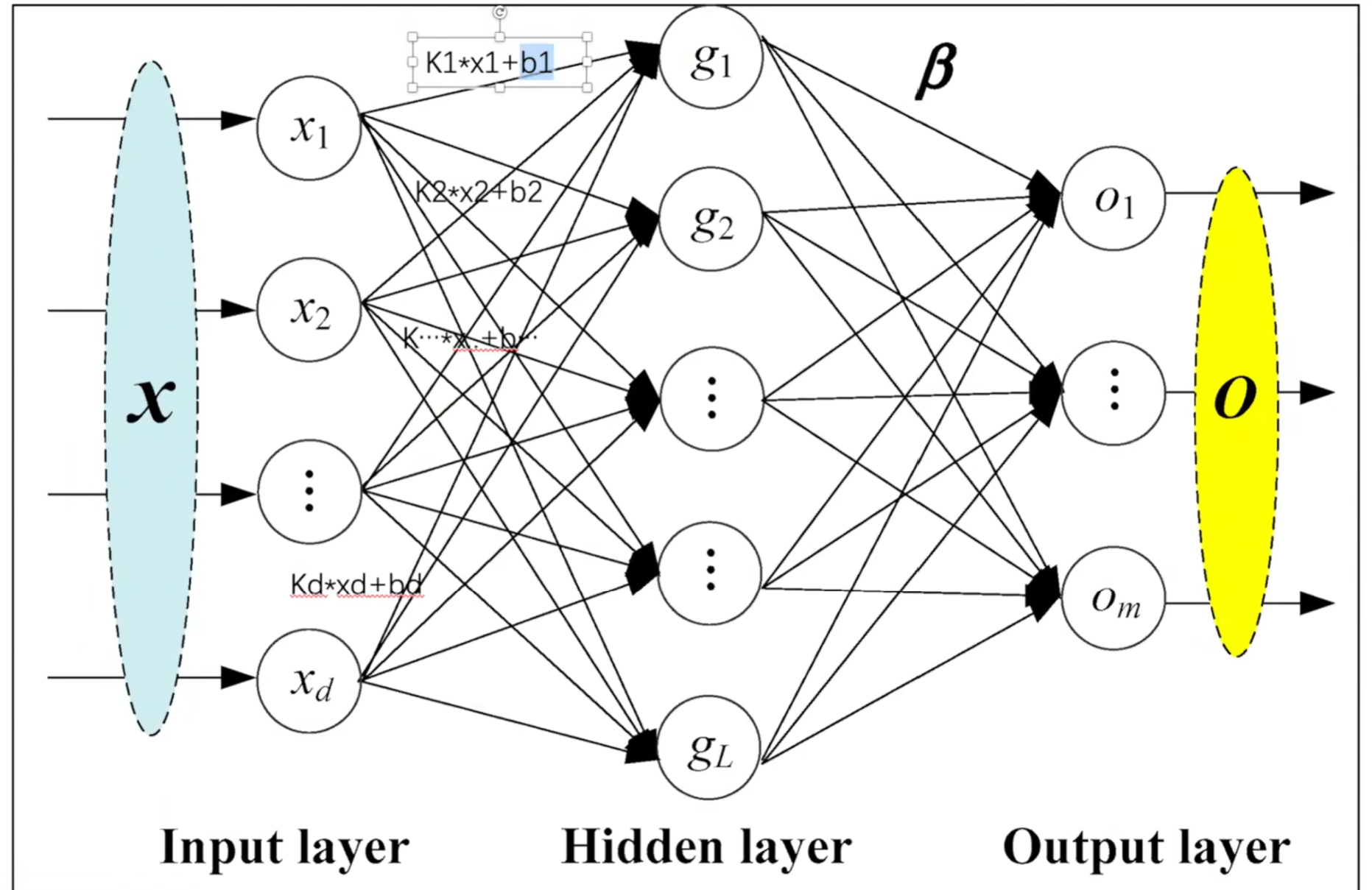
- Dropout Layers -> During training, randomly zeroes some of the elements of the input tensor with probability p (部分输入张量的元素会以p的概率变成0) -> 理论论文
Sparse Layers -> 主要用于自然语言处理(稀疏层) A simple lookup table that stores embeddings of a fixed dictionary and size. (一个简单的查找表,用来存储对应字典和大小的嵌入) This module is often used to store word embeddings and retrieve them using indices. (用来存储字词嵌入并通过索引将它们恢复)
- 线性层示例
1
2
3
4
5
6
7
8
class mymodel(nn.Module):
def __init__(self):
super().__init__()
self.linear1 = nn.Linear(in_features, out_features)
def forward(self, input):
output = self.linear1(input)
return output
- 随手学一个
torch.flatten()
1
2
3
4
5
6
7
8
9
10
11
12
13
torch.flatten(input, start_dim, end_dim)
# input 输入一个张量
# start_dim 转换成 start_dim + 1 维度
t = torch.tensor([[[1, 2],
[3, 4]],
[[5, 6],
[7, 8]]])
torch.flatten(t)
# tensor([1, 2, 3, 4, 5, 6, 7, 8])
torch.flatten(t, start_dim=1)
# tensor([[1, 2, 3, 4],
# [5, 6, 7, 8]])
This post is licensed under CC BY 4.0 by the author.