【pytorch笔记】损失函数反向传播与优化器optimizer
损失函数反向传播与优化器optimizer
【pytorch笔记】损失函数反向传播与优化器optimizer
前言
- 使用教程来自小土堆pytorch教程
- 配置环境:torch2.0.1+cu118与对应torchaudio和torchvision
目标
- 了解如何用
loss计算输出与目标之间的差距 - 了解如何用
loss为更新输出提供一定的依据,即应用于backward反向传播上 - 了解如何使用优化器
optimizer
L1loss
- 相减后得到损失值
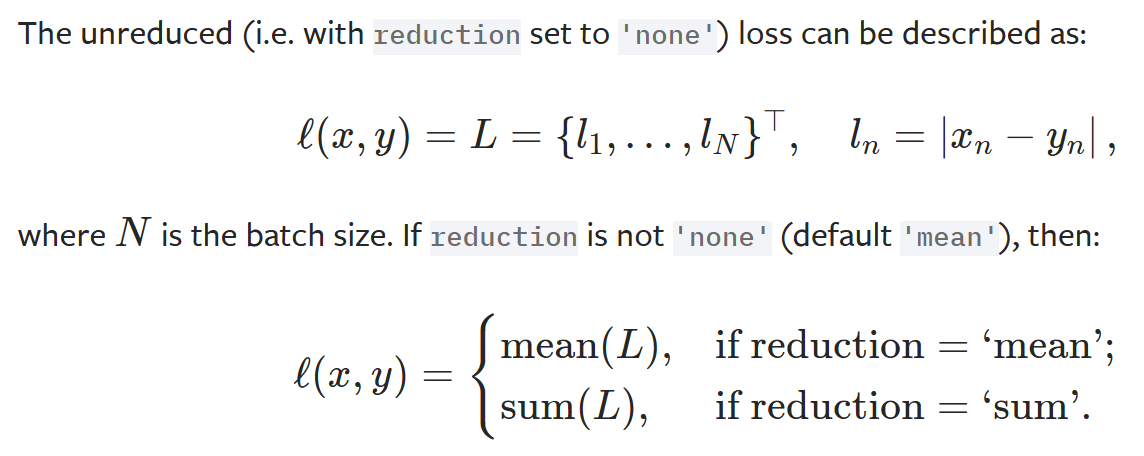
1
2
3
4
5
input = torch.tensor([1, 2, 5], dtype=torch.float32)
target = torch.tensor([1, 2, 3], dtype=torch.float32)
l1loss = nn.L1Loss() # 默认是"mean"模式
loss_1 = l1loss(input, target)
print(loss_1) # tensor(0.6667)
MSEloss
- Mean Squared Error 均方误差

1
2
3
MSEloss = nn.MSELoss() # 默认是"mean"模式
loss_MSE = MSEloss(input, target)
print(loss_MSE) # tensor(1.3333)
CrossEntropyLoss - 交叉熵误差 与 optimizer 优化器
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
class toy_model(nn.Module):
def __init__(self):
super().__init__()
# 不加上面这行会报错:
# AttributeError: cannot assign module before Module.__init__() call
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, padding=2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, padding=2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
myDevice = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
dataset = torchvision.datasets.CIFAR10("tmp-tudui/CIFAR10", train=False,
transform=torchvision.transforms.ToTensor(),
download=False)
dataloader = DataLoader(dataset, batch_size=32)
model = toy_model().to(myDevice) # 让GPU去干这个事情
loss = nn.CrossEntropyLoss() # 损失
optimizer = torch.optim.SGD(model.parameters(), lr = 0.01)
# 进行20轮训练 epoch
for epoch in range(20):
# 我们只想看每一轮的loss是多少,而不是去看每一个数据在每一轮中的loss
running_loss = 0.0
for data in dataloader:
imgs, label = data
imgs, label = imgs.to(myDevice), label.to(myDevice)
output = model(imgs)
res_loss = loss(output, label)
# 将可以调节参数的梯度都调为0
optimizer.zero_grad()
# 注意 是对得到的损失结果进行.backward()
res_loss.backward() # 应用给反向传播
# 对每个参数进行调优
optimizer.step()
running_loss = running_loss + res_loss
# tensor(712.3653, grad_fn=<AddBackward0>)
running_loss = running_loss + res_loss.item()
# 算出来是平均误差 716.3158648014069
running_loss = running_loss + res_loss.item() * imgs.size(0) # 乘以批次 N
# 总误差是 22874.690788269043
# 每一轮都输出一个损失
print(running_loss)
注意是给得到的损失结果应用反向传播 .backward()
optimizer.zero_grad() - res_loss.backward() - optimizer.step() - 这三步不能颠倒
记得用
item()imgs.size(0), imgs.size(1), imgs.size(2), imgs.size(3) 对应 N C H W
This post is licensed under CC BY 4.0 by the author.