【AI程设】Pandas 变形与连接
AI程设课上教的 Pandas 变形与连接
内容来源于 北京交通大学 计算机学院 人工智能专业 大二专业课 人工智能程序设计
Pandas 变形
- 变形操作指改变数据表的结构
变形操作有3种:
列中元素转移至列索引
列索引转移至列
基于规则将某一列沿横向或纵向扩张
长宽表概念:
- 长表和宽表是针对某个属性而言的。在数据表中,如果某属性以列的形式存在,则称该表是关于这个属性的长表。如果将该属性的各取值作为列索引,则称该表是关于这个属性的宽表
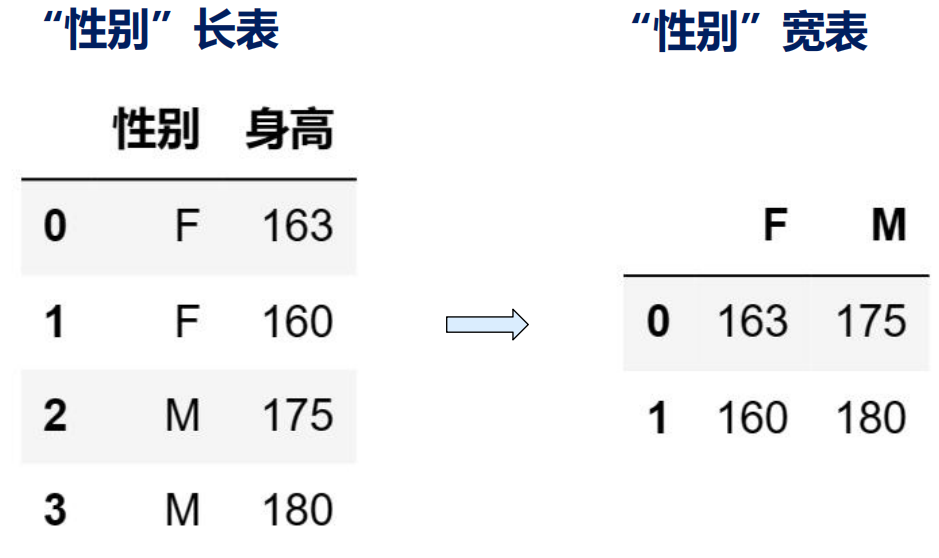
长表变宽表
pivot(),pivot_table()pivot(index = ..., columns = ..., values = ...)新表的行索引
index待转换的属性列
columns新表的数据列
valuespivot()必须满足唯一性要求,即参数index和columns对应的组合必须唯一
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
df = pd.DataFrame({'Class': [1, 1, 2, 2],
'Name': ['A', 'A', 'B', 'B'],
'Subject': ['Chinese', 'Math', 'Chinese', 'Math'],
'Score': [80, 75, 90, 85] })
'''
Class Name Subject Score
0 1 A Chinese 80
1 1 A Math 75
2 2 B Chinese 90
3 2 B Math 85
'''
df.pivot(index = 'Name', columns = 'Subject', values = 'Score')
'''
Subject Chinese Math
Name
A 80 75
B 90 85
'''
df2 = df
df2.loc[1, 'Subject'] = 'Chinese'
df2.pivot(index = 'Name', columns = 'Subject', values = 'Score')
# 不满足唯一性 会报错
# pivot() 函数的参数可以是列表
df_unpivot.pivot(index = ['Class', 'Name'],
columns = ['Subject','Type'],
values = ['Score', 'Rank'])
'''
Score Rank
Subject Chinese Math Chinese Math
Type Mid Final Mid Final Mid Final Mid Final
Class Name
1 A 80 75 90 85 10 15 20 7
2 B 85 65 92 88 21 15 6 21
'''
当某些变形限于
pivot()对唯一性的要求无法实现时,可以用pivot_table()实现其中
aggfunc = ...可以写聚合函数,也可以写自定义函数margin = boolean可以实现边际聚合透视
1
2
3
4
5
6
7
8
9
df2.pivot_table(index = 'Name', columns = 'Subject', values = 'Score', aggfunc='mean', margins = True)
'''
Subject Chinese Math All
Name
A 77.500000 NaN 77.5
B 90.000000 85.0 87.5
All 81.666667 85.0 82.5
'''
宽表变长表
- 宽表变长表
melt(),wide_to_long(),其中melt()函数是pivot()函数的逆函数 id_vars等价于pivot() indexvalue_vars等价于pivot columns的取值var_name等价于pivot columns的列索引value_name等价于pivot values
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
df = pd.DataFrame({'Class': [1, 2],
'Name': ['A', 'B'],
'Chinese' : [80, 90],
'Math': [80, 75] })
'''
Class Name Chinese Math
0 1 A 80 80
1 2 B 90 75
'''
df_melted = df.melt(id_vars = 'Name',
value_vars = ['Chinese', 'Math'],
var_name = 'Subject',
value_name = 'Score')
'''
Name Subject Score
0 A Chinese 80
1 B Chinese 90
2 A Math 80
3 B Math 75
'''
索引变形
unstack()将行索引转换为列索引DataFrame.unstack(level=-1, fill_value=None)level:指定要转换的行级别,默认是最内层。fill_value:用来填充缺失值。
stack()将列索引转换为行索引,将宽格式的数据转换为长格式。DataFrame.stack(level=-1, dropna=True)level:指定要转换的列级别,默认是最内层。dropna:是否丢弃缺失值,默认为True
从 0 开始, 0 对应最外层, 1 对应下一层,以此类推
stack()会将结果中缺失值位置的行删去,而unstack()会保留方向记忆法
stack():“堆叠” —— 将 列 转换为 行。即将 宽 表格“堆叠”成 长 表格。类比:把多层的文件夹压扁,变成一列文件。
unstack():“展开” —— 将 行 转换为 列。即将 长 表格“展开”成 宽 表格。类比:把一列文件重新整理成多层文件夹。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
df = pd.DataFrame(np.ones((4, 2)),
index = pd.Index([('A', 'cat', 'big'),
('A', 'dog', 'small'),
('B', 'cat', 'big'),
('B', 'dog','small')]),
columns = ['index_1', 'index_2'])
'''
index_1 index_2
A cat big 1.0 1.0
dog small 1.0 1.0
B cat big 1.0 1.0
dog small 1.0 1.0
'''
df.stack()
'''
A cat big index_1 1.0
index_2 1.0
dog small index_1 1.0
index_2 1.0
B cat big index_1 1.0
index_2 1.0
dog small index_1 1.0
index_2 1.0
dtype: float64
'''
df.unstack()
'''
index_1 index_2
big small big small
A cat 1.0 NaN 1.0 NaN
dog NaN 1.0 NaN 1.0
B cat 1.0 NaN 1.0 NaN
dog NaN 1.0 NaN 1.0
'''
.reset_index()可以对索引进行重置,将各种索引转变成普通列,之后再进行各种处理操作
Pandas 连接
连接有两种形式:
关系连接
方向连接
其中,关系连接的方式有左、右、内、外
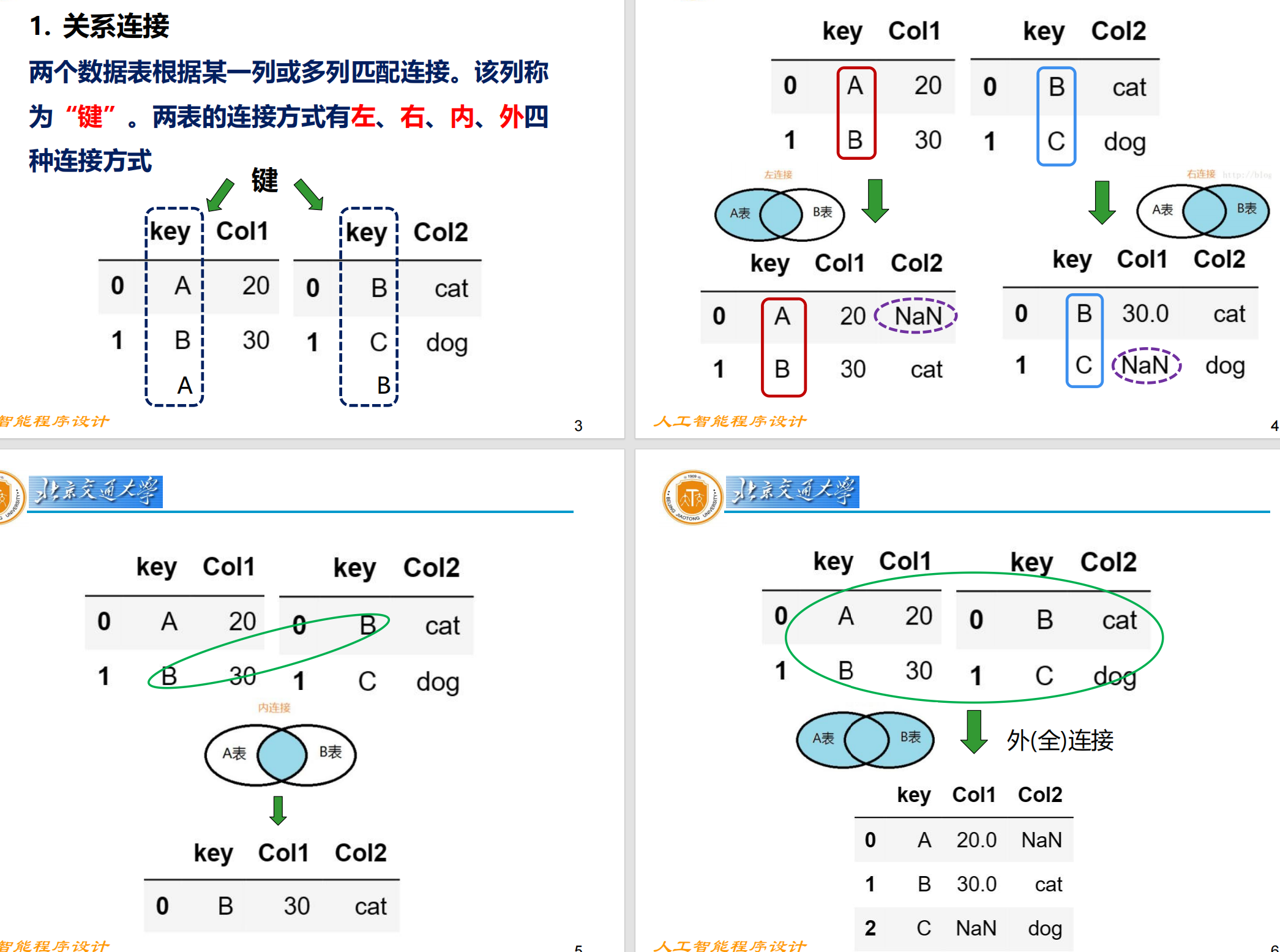
merge() 关系连接
两侧表的键在列上出现
how = "inner" / "left" / "right" / "outer"指定连接方式on = "..."指定合并的列名当要合并的键列在左右两个
DataFrame中名字不同时,使用left_on和right_on分别指定左右DataFrame的键列suffixes = ('...', '...')为同名列添加后缀,以区分来源validate = "1:1" / "1:m" / "m:1" / "m:m"检查左右两表的唯一性
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
import pandas as pd
# 创建第一个示例 DataFrame
data1 = {
'Class': [1, 1, 2, 2],
'Name': ['A', 'A', 'B', 'B'],
'Subject': ['Chinese', 'Math', 'Chinese', 'Math'],
'Score': [80, 75, 90, 85]
}
df1 = pd.DataFrame(data1)
# 创建第二个示例 DataFrame
data2 = {
'StudentID': [1, 2, 3, 4],
'Age': [15, 16, 15, 16],
'Gender': ['F', 'M', 'F', 'M']
}
df2 = pd.DataFrame(data2)
'''
DataFrame 1:
Class Name Subject Score
0 1 A Chinese 80
1 1 A Math 75
2 2 B Chinese 90
3 2 B Math 85
DataFrame 2:
StudentID Age Gender
0 1 15 F
1 2 16 M
2 3 15 F
3 4 16 M
'''
merged_on = pd.merge(df1, df2, how='inner', on='Class')
# 注意:在本示例中,df2 中没有 Class 列,会导致合并结果为空
# 假设 df1 的 'Class' 对应 df2 的 'StudentID'
merged_custom = pd.merge(df1, df2, how='inner', left_on='Class', right_on='StudentID')
'''
使用 left_on 和 right_on 参数的内连接结果:
Class Name Subject Score StudentID Age Gender
0 1 A Chinese 80 1 15 F
1 1 A Math 75 1 15 F
2 2 B Chinese 90 2 16 M
3 2 B Math 85 2 16 M
'''
# 在 df2 中添加一个与 df1 重名的列
df2['Name'] = ['C', 'D', 'E', 'F']
df2['Class'] = df2['StudentID']
df2 = df2.drop('StudentID', axis=1)
print("\n修改后的 DataFrame 2:\n", df2)
merged_suffixes = pd.merge(df1, df2, how='outer', on='Class', suffixes=('_df1', '_df2'))
print("\n使用 suffixes 参数的外连接结果:\n", merged_suffixes)
'''
修改后的 DataFrame 2:
Age Gender Name Class
0 15 F C 1
1 16 M D 2
2 15 F E 3
3 16 M F 4
使用 suffixes 参数的外连接结果:
Class Name_df1 Subject Score Age Gender Name_df2
0 1 A Chinese 80.0 15 F C
1 1 A Math 75.0 15 F C
2 2 B Chinese 90.0 16 M D
3 2 B Math 85.0 16 M D
4 3 NaN NaN NaN 15 F E
5 4 NaN NaN NaN 16 M F
'''
join() 关系连接
两侧表的键在索引上出现
how = "inner" / "left" / "right" / "outer"指定连接方式on = "..."指定合并的列名lsuffix = '_left'与rsuffix = '_right'指定同名列的后缀
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
import pandas as pd
# 创建第一个示例 DataFrame
data1 = {
'EmployeeID': [1, 2, 3, 4],
'Name': ['Alice', 'Bob', 'Charlie', 'David'],
'Department': ['HR', 'Engineering', 'Marketing', 'Finance']
}
df1 = pd.DataFrame(data1)
print("DataFrame 1:\n", df1)
# 创建第二个示例 DataFrame
data2 = {
'EmployeeID': [3, 4, 5, 6],
'Salary': [70000, 80000, 75000, 72000],
'Bonus': [5000, 6000, 5500, 5200]
}
df2 = pd.DataFrame(data2)
print("\nDataFrame 2:\n", df2)
'''
DataFrame 1:
EmployeeID Name Department
0 1 Alice HR
1 2 Bob Engineering
2 3 Charlie Marketing
3 4 David Finance
DataFrame 2:
EmployeeID Salary Bonus
0 3 70000 5000
1 4 80000 6000
2 5 75000 5500
3 6 72000 5200
'''
# 将 EmployeeID 设置为索引
df1_index = df1.set_index('EmployeeID')
df2_index = df2.set_index('EmployeeID')
# 使用 join() 进行左连接
joined_left = df1_index.join(df2_index, how='left')
print("\n使用 join() 进行左连接的结果:\n", joined_left)
'''
使用 join() 进行左连接的结果:
Name Department Salary Bonus
EmployeeID
1 Alice HR NaN NaN
2 Bob Engineering NaN NaN
3 Charlie Marketing 70000.0 5000.0
4 David Finance 80000.0 6000.0
'''
concat() 方向连接
axis = 0 / 1垂直上下连接 / 水平左右连接join = "outer" / "inner"并集,保留所有标签,缺失值填充为NaN/ 交集,只保留共同标签keys = ["...", "..."]区分不同的数据源如果两个表有重复索引,除非两侧表所有元素的值和位置都一一对应,否则方向连接直接报错,而关系连接返回笛卡尔积
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
# 创建示例 DataFrame
df1 = pd.DataFrame({
'Class': [1, 1, 2, 2],
'Name': ['A', 'A', 'B', 'B'],
'Subject': ['Chinese', 'Math', 'Chinese', 'Math'],
'Score': [80, 75, 90, 85]
})
df2 = pd.DataFrame({
'StudentID': [1, 2, 3, 4],
'Age': [15, 16, 15, 16],
'Gender': ['F', 'M', 'F', 'M']
})
# 垂直连接两个 DataFrame
df_vertical = pd.concat([df1, df2], axis=0)
'''
垂直连接后的 DataFrame:
Class Name Subject Score StudentID Age Gender
0 1.0 A Chinese 80.0 NaN NaN NaN
1 1.0 A Math 75.0 NaN NaN NaN
2 2.0 B Chinese 90.0 NaN NaN NaN
3 2.0 B Math 85.0 NaN NaN NaN
0 NaN NaN NaN NaN 1.0 15.0 F
1 NaN NaN NaN NaN 2.0 16.0 M
2 NaN NaN NaN NaN 3.0 15.0 F
3 NaN NaN NaN NaN 4.0 16.0 M
'''
# 水平连接两个 DataFrame
df_horizontal = pd.concat([df1, df2], axis=1, join='inner')
'''
水平连接后的 DataFrame:
Class Name Subject Score StudentID Age Gender
0 1 A Chinese 80 1 15 F
1 1 A Math 75 2 16 M
2 2 B Chinese 90 3 15 F
3 2 B Math 85 4 16 M
'''
# 创建层级索引
df_combined = pd.concat([df1, df2], axis=1, keys=['df1', 'df2'])
'''
使用 keys 参数创建层级索引后的 DataFrame:
df1 df2
Class Name Subject Score StudentID Age Gender
0 1 A Chinese 80 1 15 F
1 1 A Math 75 2 16 M
2 2 B Chinese 90 3 15 F
3 2 B Math 85 4 16 M
'''
其它
assign()函数可以将Series加到DataFrame的末列,传入的参数名称为新列名
1
df1.assign(new_col_l = s1, new_col_2 = s2)
compare()函数比较两个DataFrame或者Series的不同之处并汇总展示。返回不同值所在的行列,相同则填充缺失值要求两个
DataFrame的行索引和列索引完全一致align_axis = 0 / 1按行对齐 / 按列对齐(默认)keep_shape = True / False是否与原来的行列数保持一致,默认False
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
# 这两个 DataFrame 拥有相同的行索引和列名
df1 = pd.DataFrame({
'A': [1, 2, 3],
'B': [4, 5, 6]
}, index=[0, 1, 2])
df2 = pd.DataFrame({
'A': [1, 2, 4],
'B': [4, 7, 6]
}, index=[0, 1, 2])
print("df1:\n", df1)
print("\ndf2:\n", df2)
result_compare = df1.compare(df2, align_axis=1, keep_shape=True, keep_equal=False)
'''
df1:
A B
0 1 4
1 2 5
2 3 6
df2:
A B
0 1 4
1 2 7
2 4 6
compare() 结果:
A B
self other self other
0 NaN NaN NaN NaN
1 NaN NaN 5.0 7.0
2 3.0 4.0 NaN NaN
'''
combine()结合函数func = ...一个函数,应该返回booleanfill_value = ...如果某个位置缺失,则用fill_value替代后再执行func函数,从而避免对NaN的不期望运算或错误
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# 示例 DataFrame
df1 = pd.DataFrame({'A': [1, 2, None]})
df2 = pd.DataFrame({'A': [3, None, 2]})
def choose_max(x, y):
return x.where(x >= y, y)
combined = df1.combine(df2, func=choose_max, fill_value=0)
'''
combine() 结果:
A
0 3.0
1 2.0
2 2.0
'''