【機器學習2021】Hung-Yi Lee
【機器學習2021】Hung-Yi Lee
自注意力机制(上)
Vector set as input
表示办法
独热编码 one-hot Encoding
- 缺点:缺失了语义信息
1
2
3
4
apple = [1, 0, 0, 0 ...]
banana = [0, 1, 0, 0 ...]
cat = [0, 0, 1, 0 ...]
dog = [0, 0, 0, 1 ...]
词嵌入 Word Embedding
- 具有相似语义信息的词汇在坐标系上更接近
输入
将每个词提取出来,当作一个 vector,这个 vector 也被称之为 frame
图实际上也可以当作 vector set。以社交网络图为例,若每个人是一个结点,令每个结点为一个向量,那么该向量就存储了每个人的个人信息
AI4sci 中还有分子领域,每个化学分子可以当作 vector set,使用 one-hot Encoding
1
2
3
4
H = [1, 0, 0, 0 ...] # 氢
C = [0, 1, 0, 0 ...] # 碳
O = [0, 0, 1, 0 ...] # 氧
......
输出
各类任务概述
如果每个向量都有一个标签,那么模型就是输出标签,输入输出长度相同(如输入四个向量,输出四个标签),可化为 classification 或 regression 问题
例:POS tagging 词性标注
例:给定社交网络图,决定某个人的特性(例如是否购买某产品)
如果整个输入序列有一个标签,则输入长度不限的序列,输出为一个标签
例:Sentiment analysis 语句情感分析
例:某分子特性分析
模型自行决定输出多少模型 seq2seq
- 例:Translation
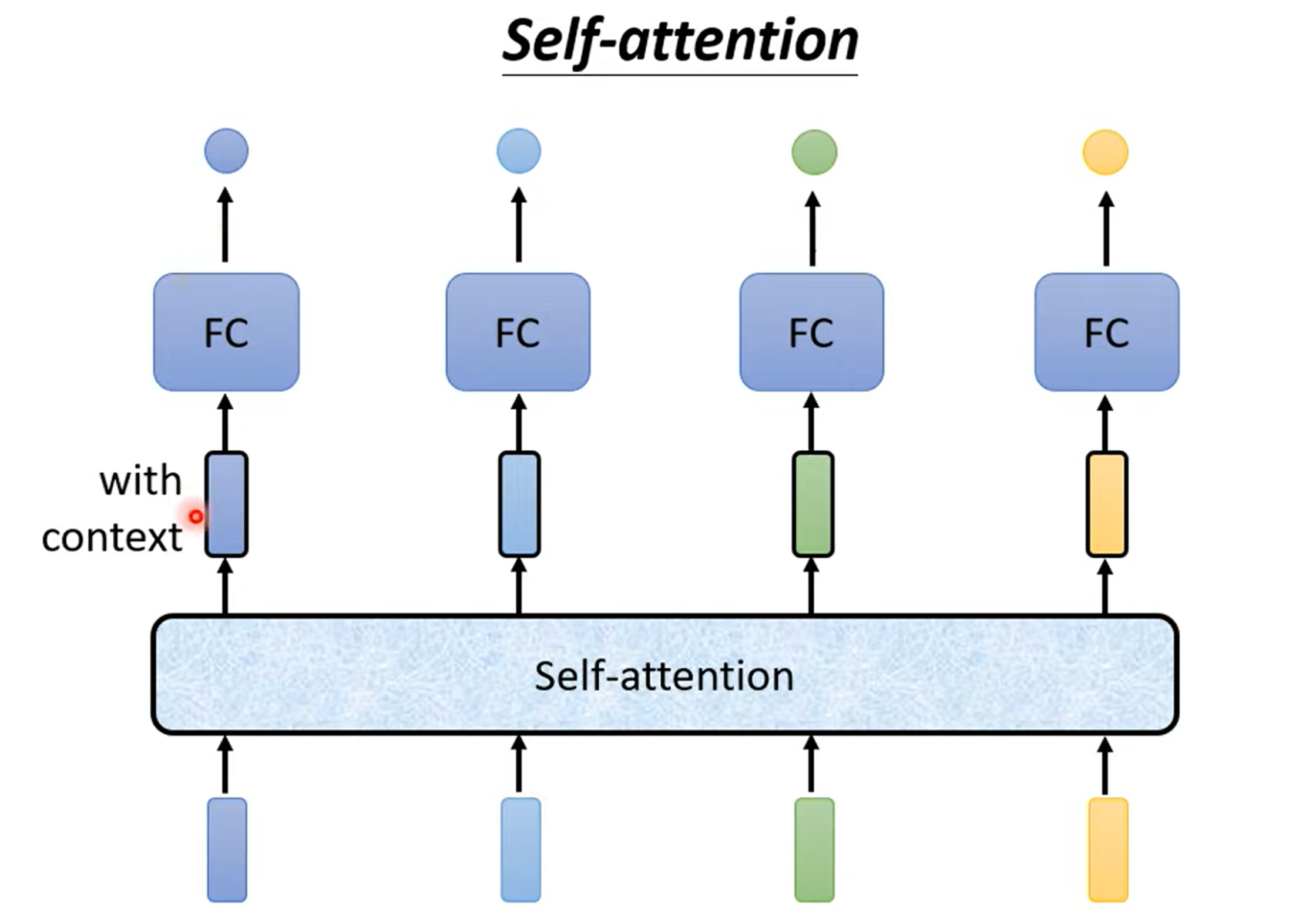
Self-attention 机制
第一种任务也称之为 Sequence Labeling
一个直觉的办法是,让每一个词汇都与一个全连接层相连,使得一个词汇对应一个词性
第一个问题:对于多义词怎么办?
解决:不妨开一个 window,使得其涵盖上下文信息,让全连接层可以参考上下文
第二个问题:window 长度怎么设定?过大 window 也显然会造成计算开销巨大
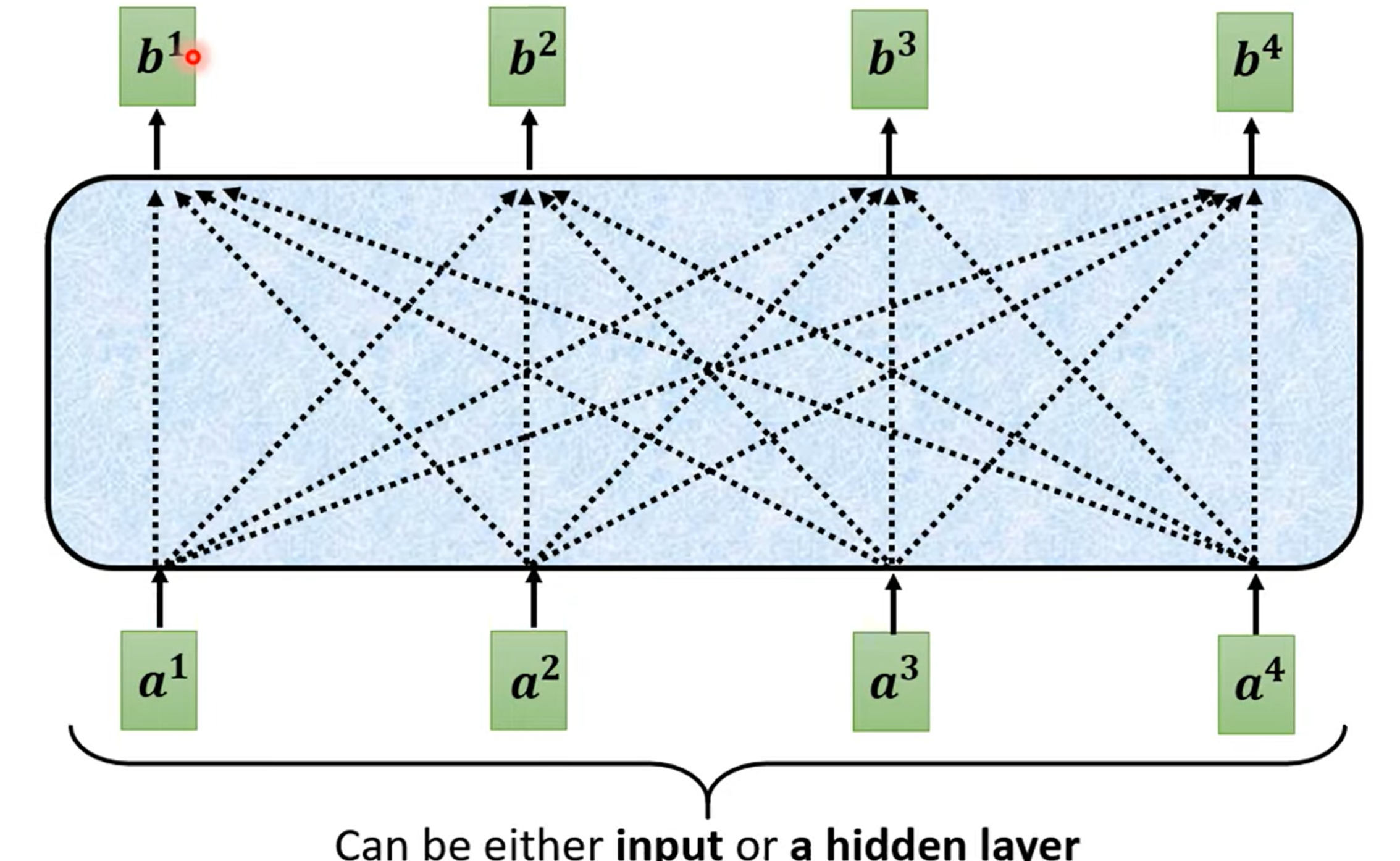
解决:引入 Self-attention 机制
Self-attention 运作机制
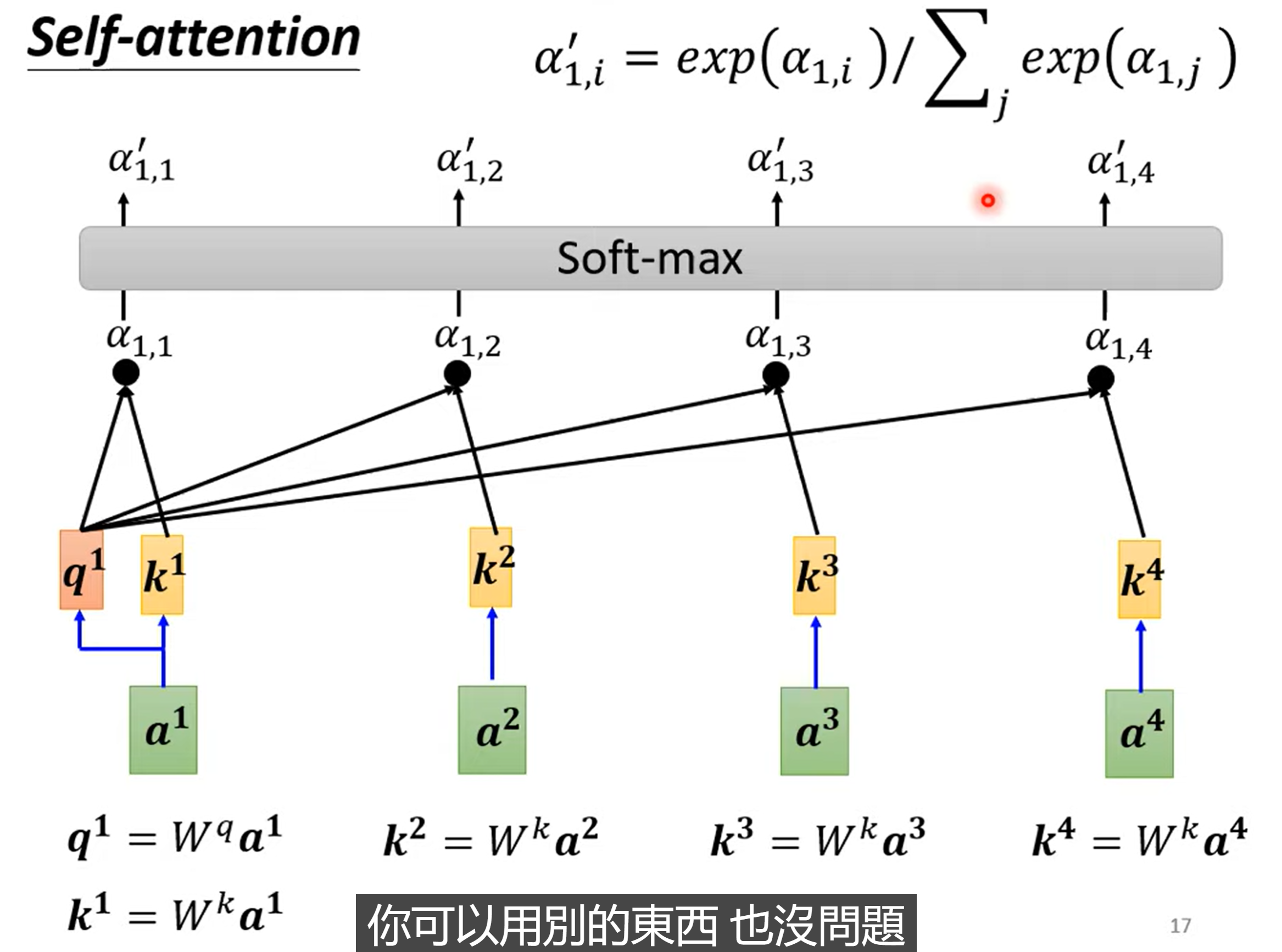
- 计算两个向量之间是否相关,使用 Dot-product(对应元素相乘后累加),query 向量与 key 向量相乘,得到 attention score
- 经过 soft-max 层(没有什么道理,换成 ReLU 或者 activation function 都可以)
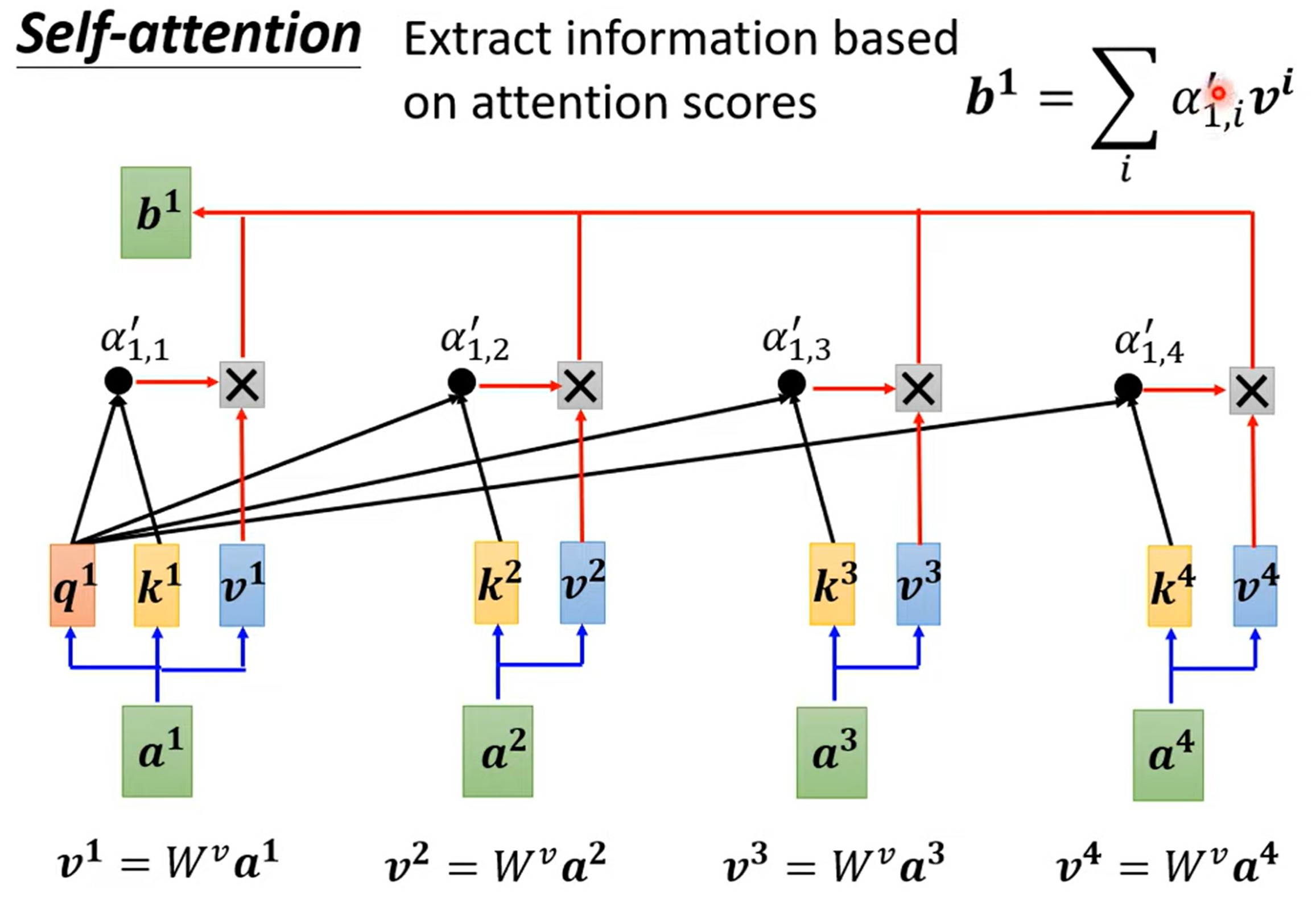
- 基于 attention score 抽取出关键信息,为 attention score 乘上一个矩阵
- 各关键信息累加,得到输出结果
自注意力机制(下)
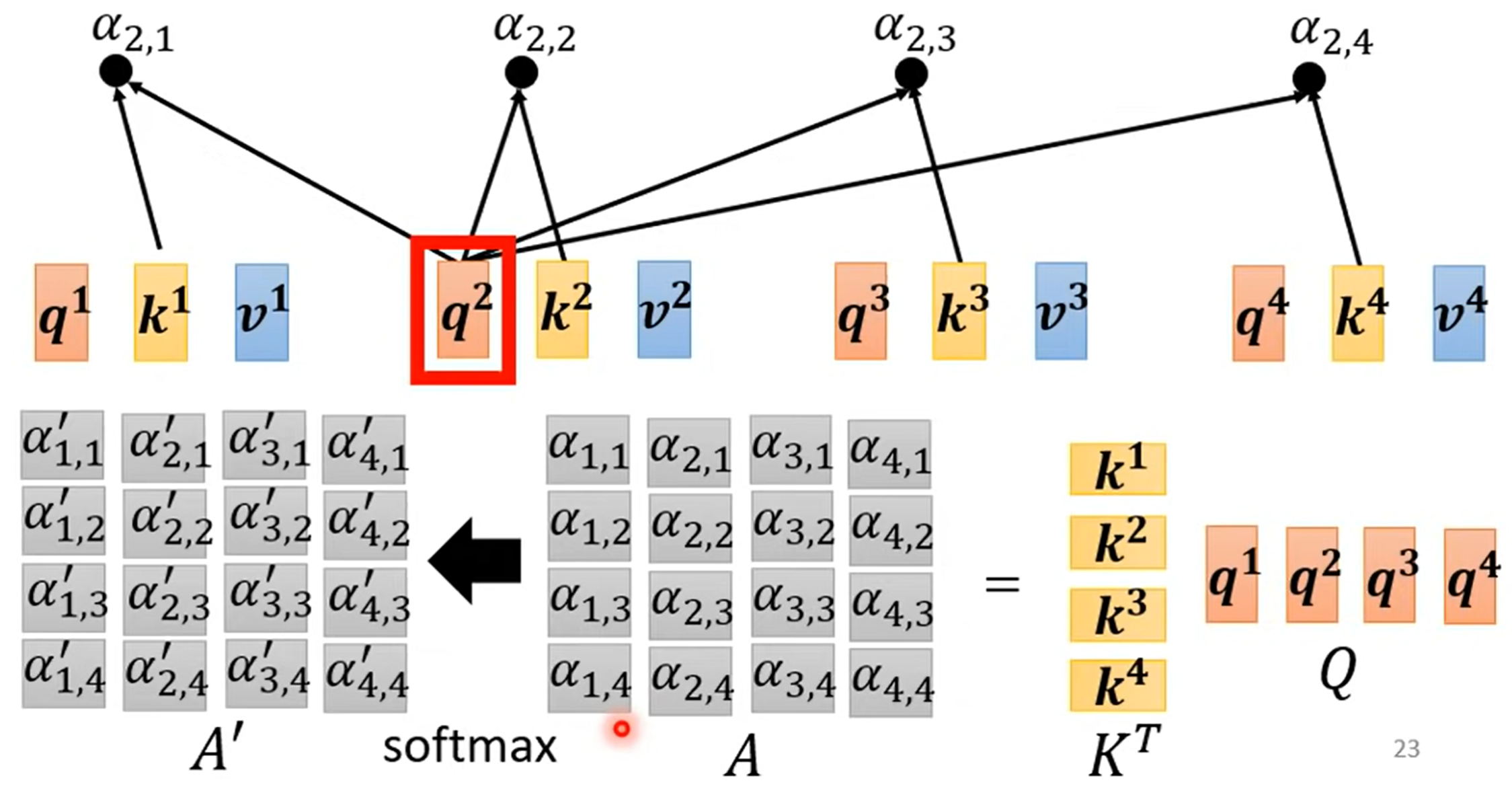
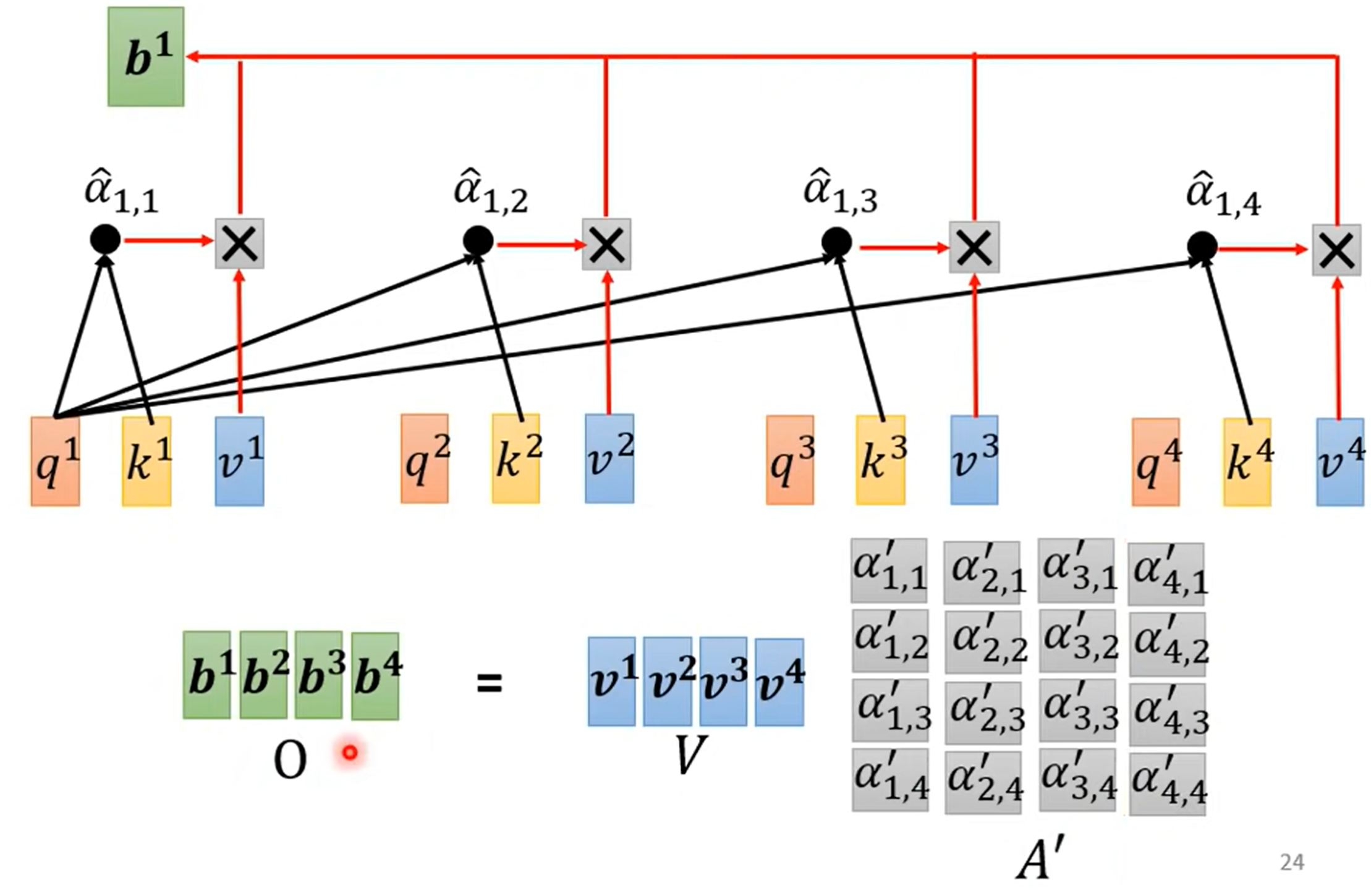
自注意力机制 - 线性代数视角
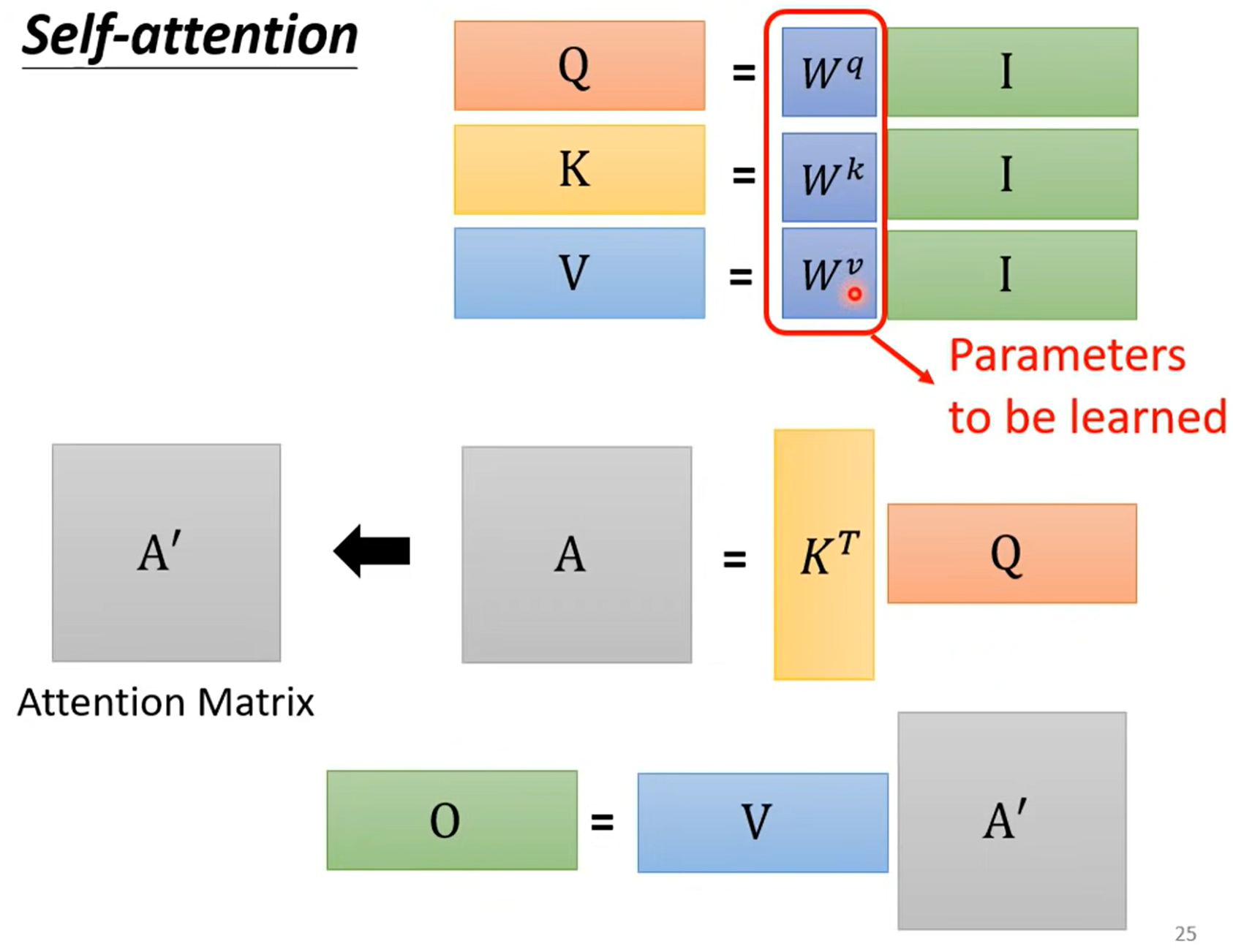
不妨使用线性代数去看待 self-attention
实际上,需要学习的参数,只有三个矩阵
Multi-head Self-attention 多头注意力机制
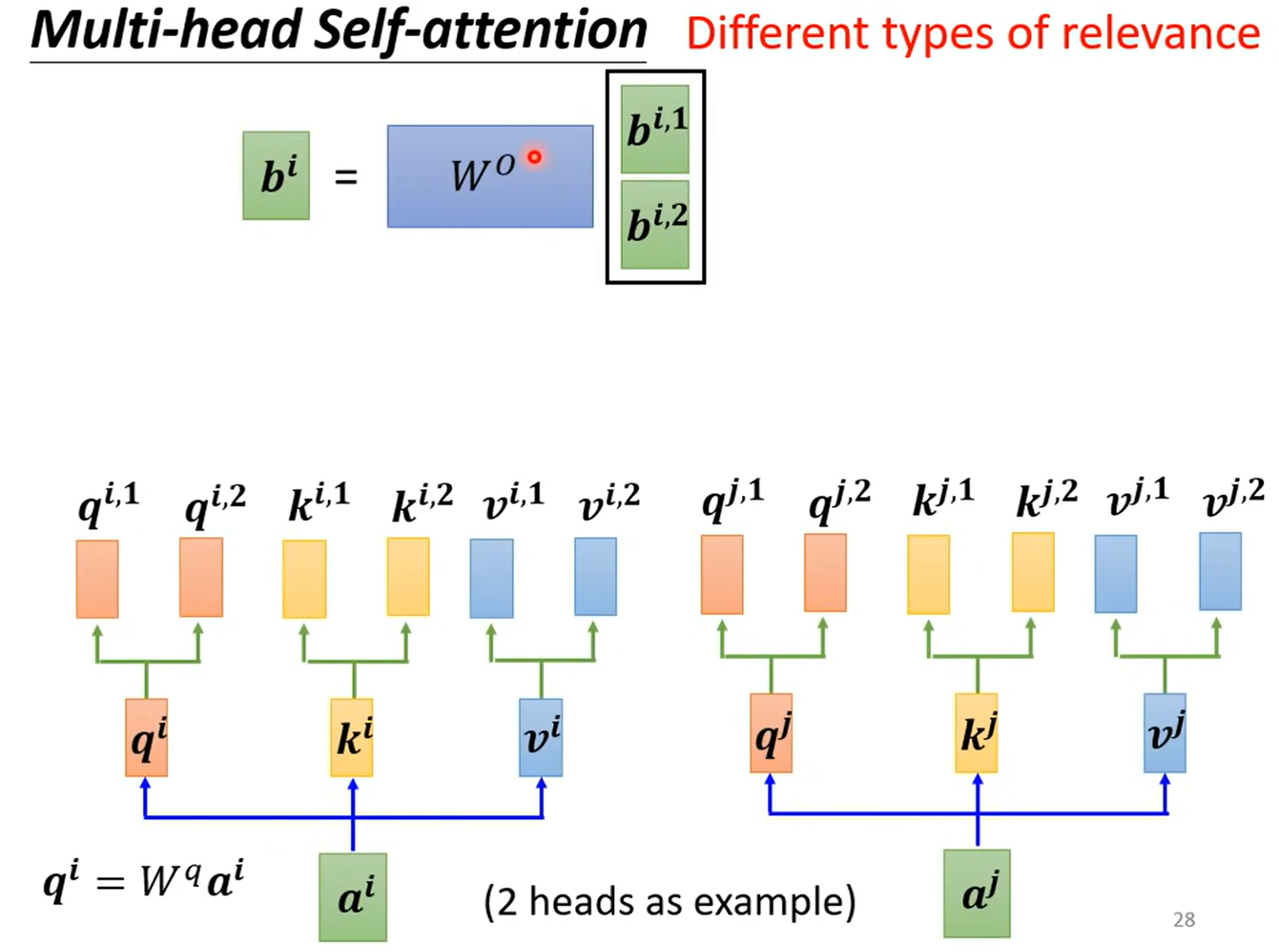
多头注意力机制就是设计 N 个矩阵,不同的矩阵负责不同种类的相关性,最后拼接起来
Positional Encoding 位置编码
我们发现,自注意力机制中缺失了位置信息。如果对你的任务而言,位置信息很重要,我们可以做到将位置信息编码进去
不妨,给每一个位置设置一个专属的位置编码 e^i
可以 hand-crafted,也可以参考 如何更好地设定 positional encoding:整个问题尚待研究,不必纠结
应用
语音识别:语音信息过长,最终的注意力矩阵也会很大,时间空间内存消耗巨大,故引入 Truncated Self-attention,我们只用看一个小范围就能判断了
self-attention for graph - GNN 的一种:每个结点只用关注相连的结点即可,参考邻接矩阵
self-attention v.s. CNN
CNN 可以看作是一种简化版的 self-attention,因为它只关注一小部分范围的图像
self-attention 则关注全部图像
self-attention 更加 flexible,需要更大的数据量,否则容易过过拟合;CNN 则相反
self-attention v.s. RNN
RNN 中,后面一个 vector 为了做到考虑前面的 vector,必须把前面的 vector 存到 memory 中
RNN 做不到平行化产生数据,必须一个一个地处理
其它
Transformer (上) + (下)
是什么
sequence to sequence (seq2seq) 模型
input a sequence, output a sequence
由模型 自行决定 输出长度
应用
speech recognition, machine translation, speech translation (for language without text) …
Text-To-Speech (TTS) Synthesis:文本的语音合成
Seq2seq for Chatbot:文字本身可以被看作是一个 vector sequence -> Natural Language Processing (NLP) 领域
syntactic parsing:句法分析(分析词性等),远古时期有人把语法当作一种语言,把上古时期人们用来翻译的方式套在上面,上古神兽时期参考文献,据说是直接梯度下降训练,就成了(?
Object detection:参考文献 01
怎么做 Seq2seq
通常来说:Input -> Encoder -> Decoder -> Ouput
主角:Transformer
Encoder 部分
输入向量,输出向量
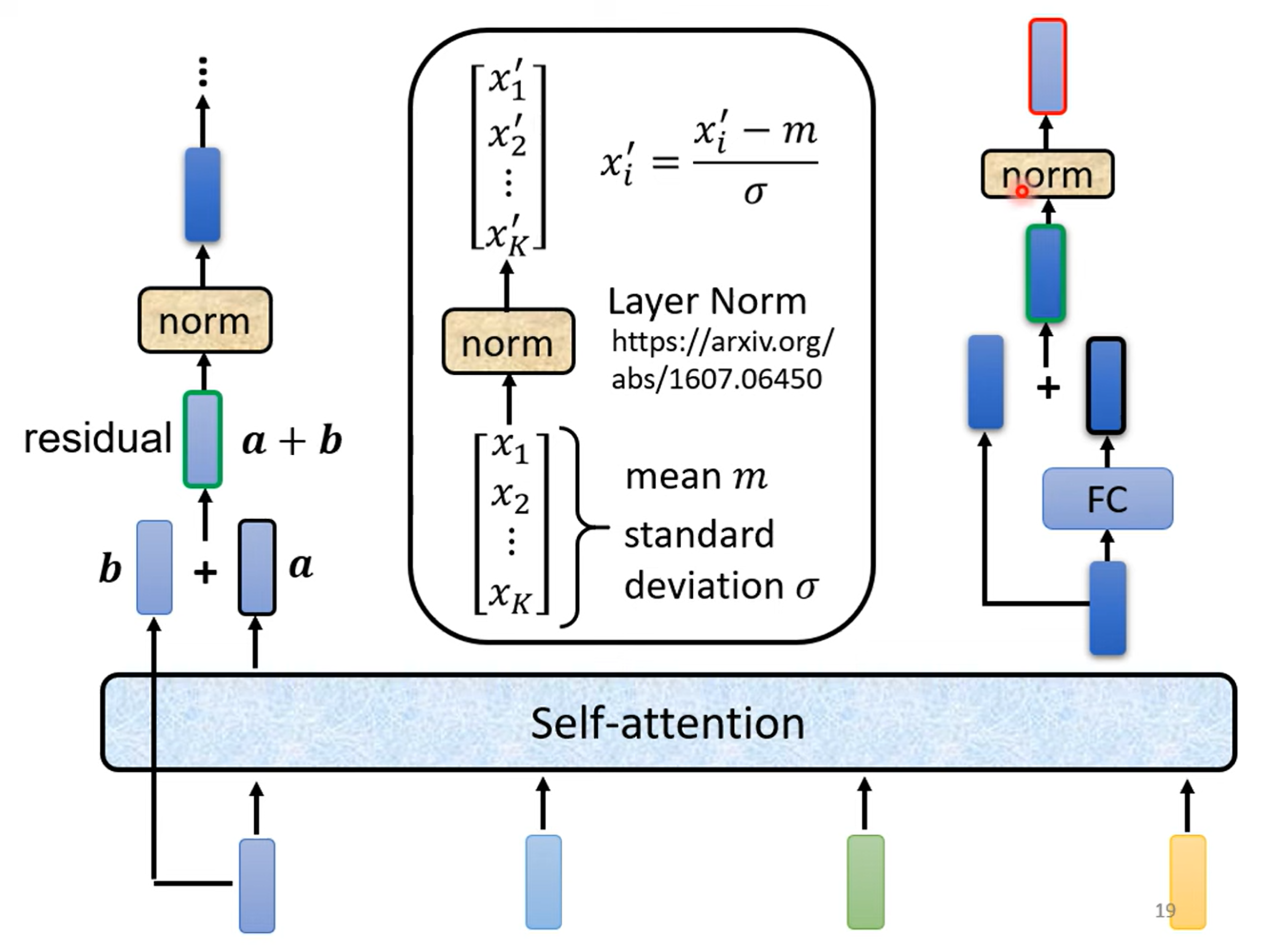
每个 block 不能被看作是一个 layer,因为 block 里面有很多 layer,以其中一个 block 为例:
首先是 self-attention 层,采取 residual connection 办法
接一个 layer normalization 层,需计算平均值与标准差
输出结果接一个 Fully-connected 层,采取 residual connection 办法
再接一个 layer normalization 层
能不能再优化呢?原论文的 encoder 架构就是最 optimal 的吗? -> 参考文献 01,参考文献 02:为什么不做 Batch Norm
Decoder 部分
Autoregressive
将 Encoder 输出的 Seq 输入到 Decoder 里,Decoder 再输出一个 seq
存在一个 Begin Of Sentence (BOS)、为一个特殊的 token
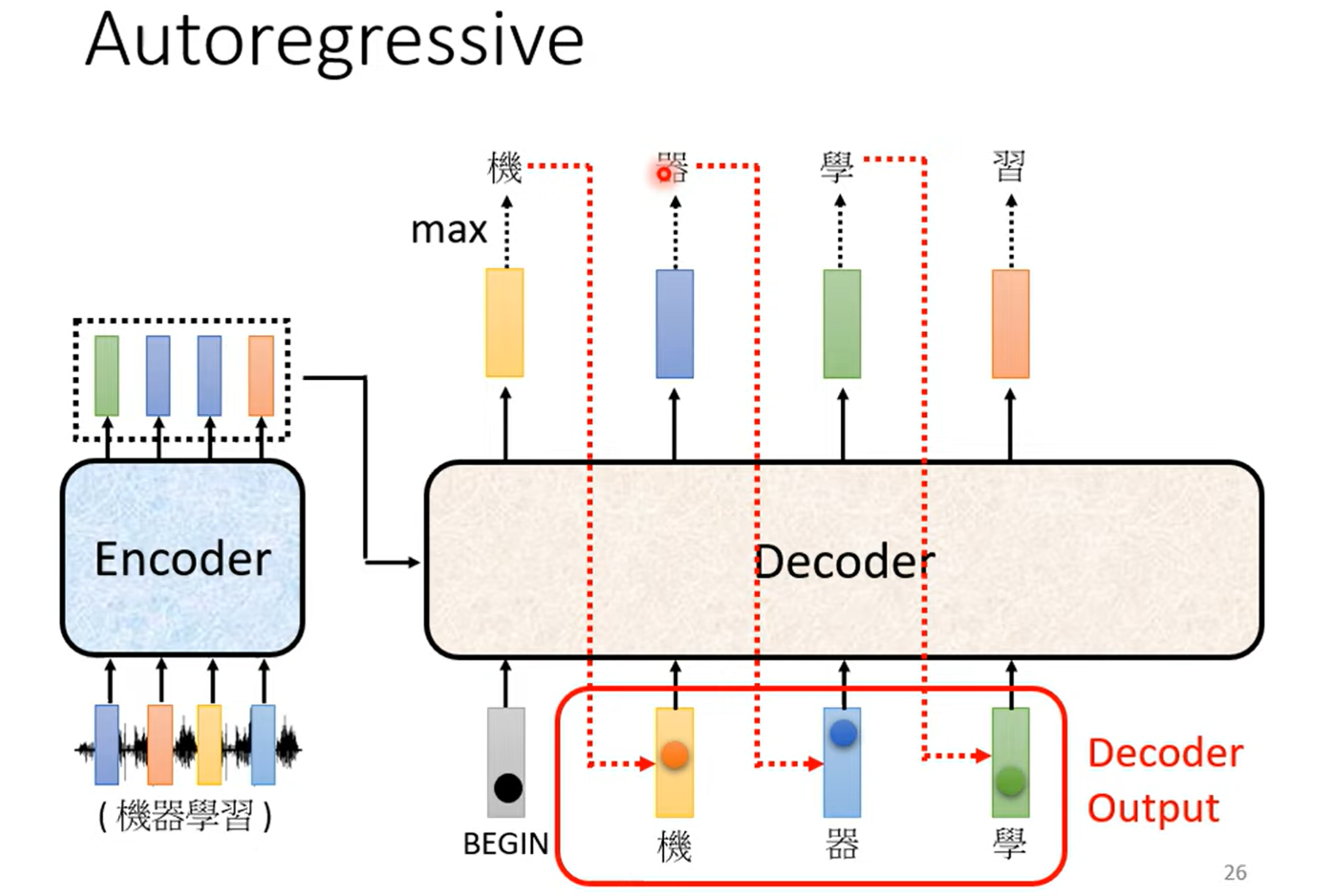
不会出现 Error Propagation (一步错,步步错) 吗?
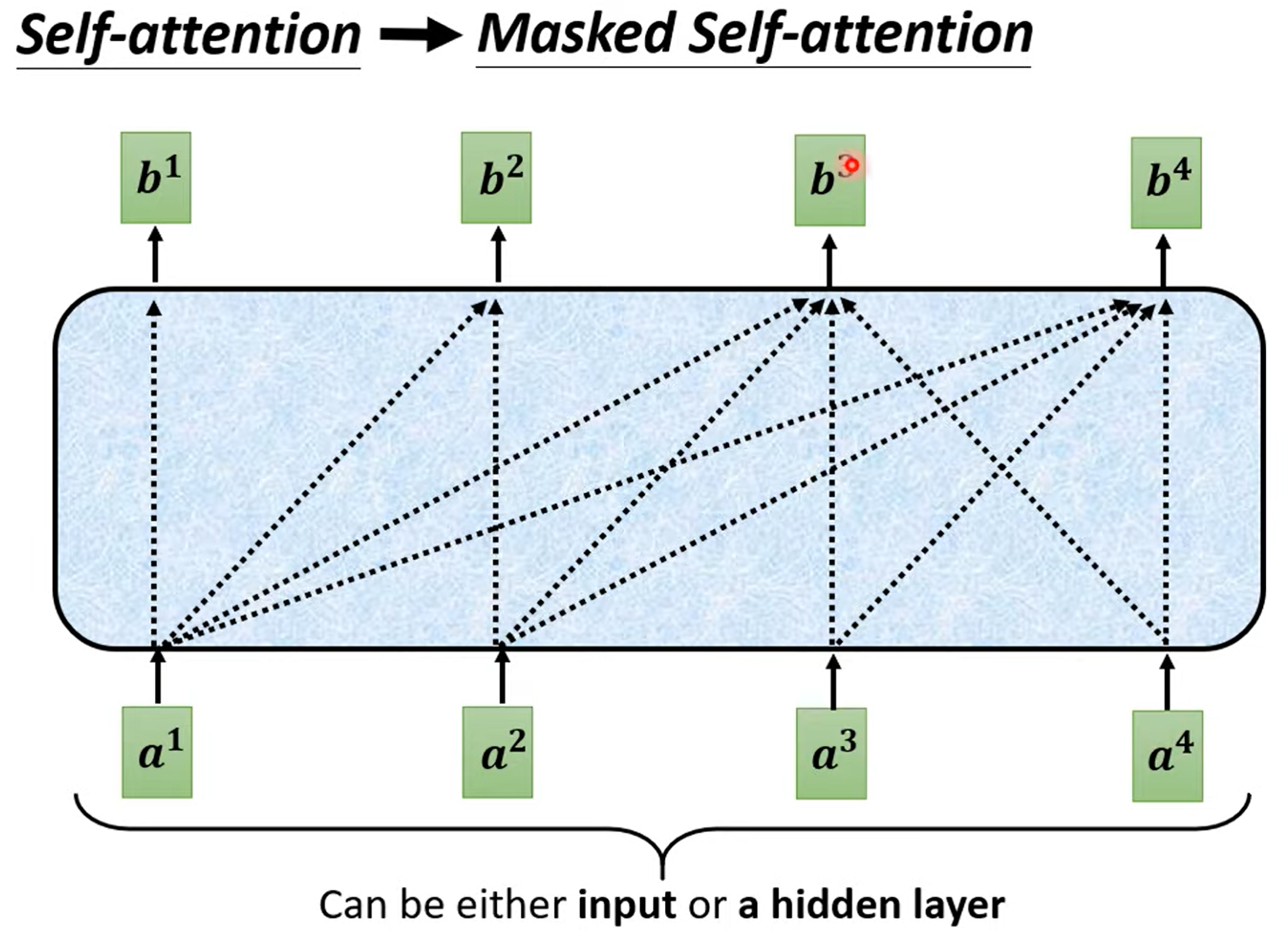
注意到 Masked Self-attention - 不看后面的输入,只关注已有的输入:why?
Consider how does decoder work
必须先有上一个字,才能有下一个字
还会有 END token,以做到“就输出这么多”
Non-Autoregressive (NAT)
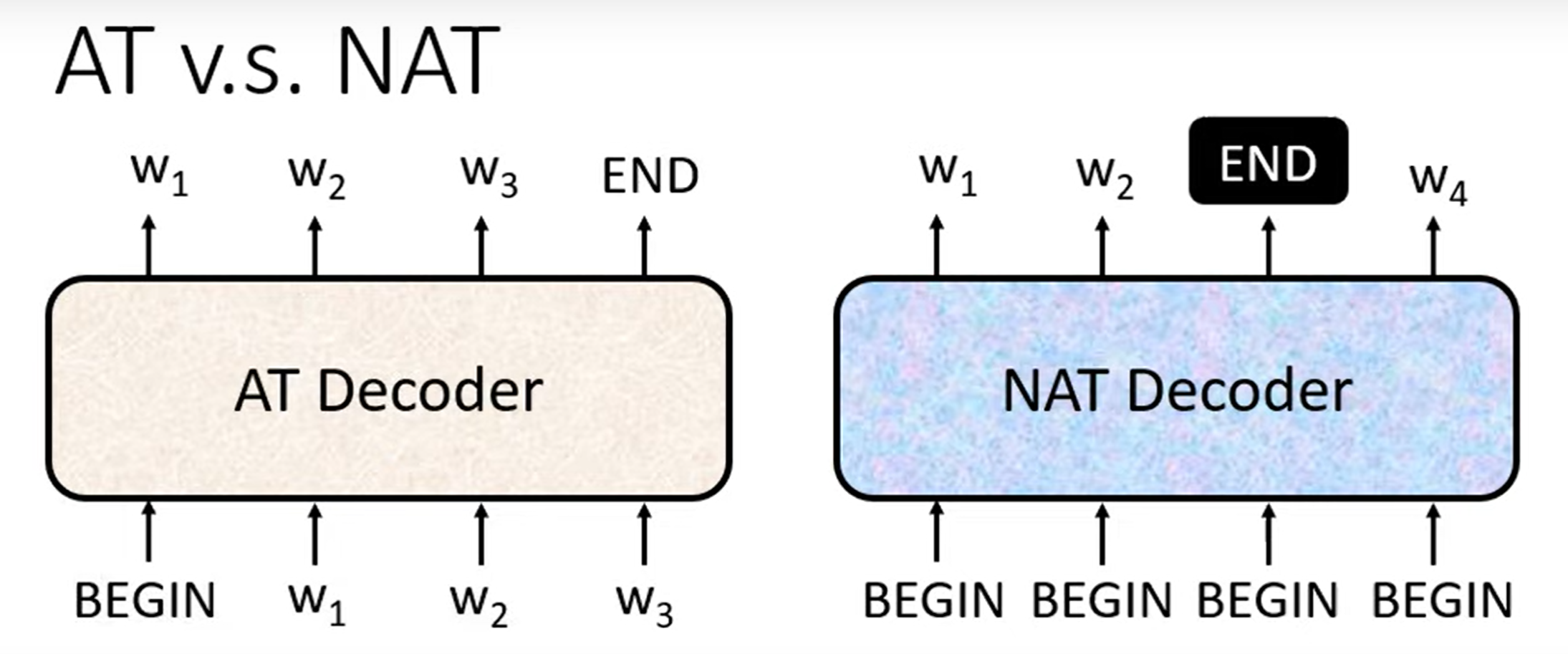
NAT 如何判断输出长度
Another predictor for output length
Output a very long seq, ignore tokens after END
优点:
parallel(与 AT 相比,AT 要生成 100 个字的句子,就需要进行 100 次 decode)
controllable output length
缺点:
- NAT is usually worse than AT
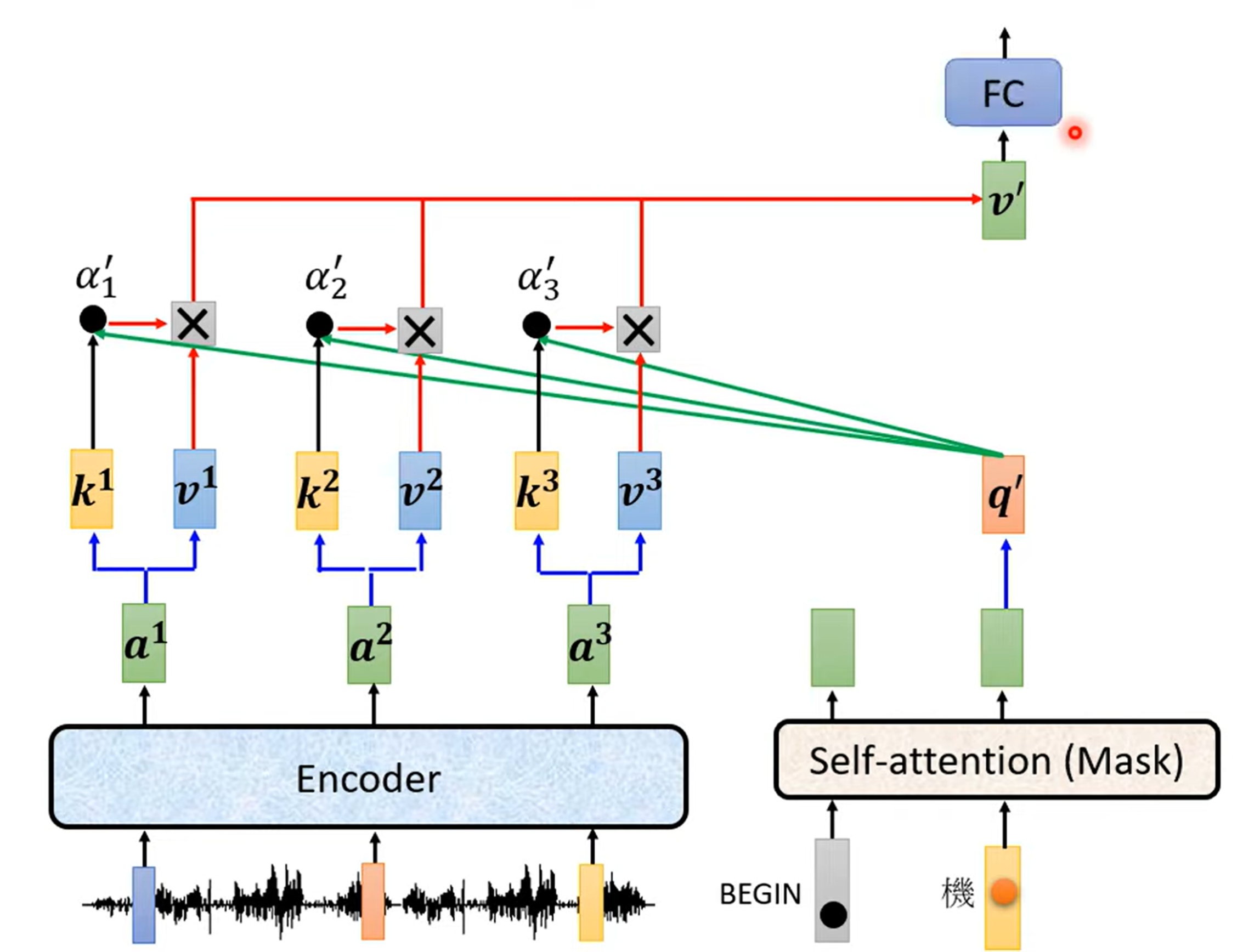
Encoder - Decode 之间怎么连接
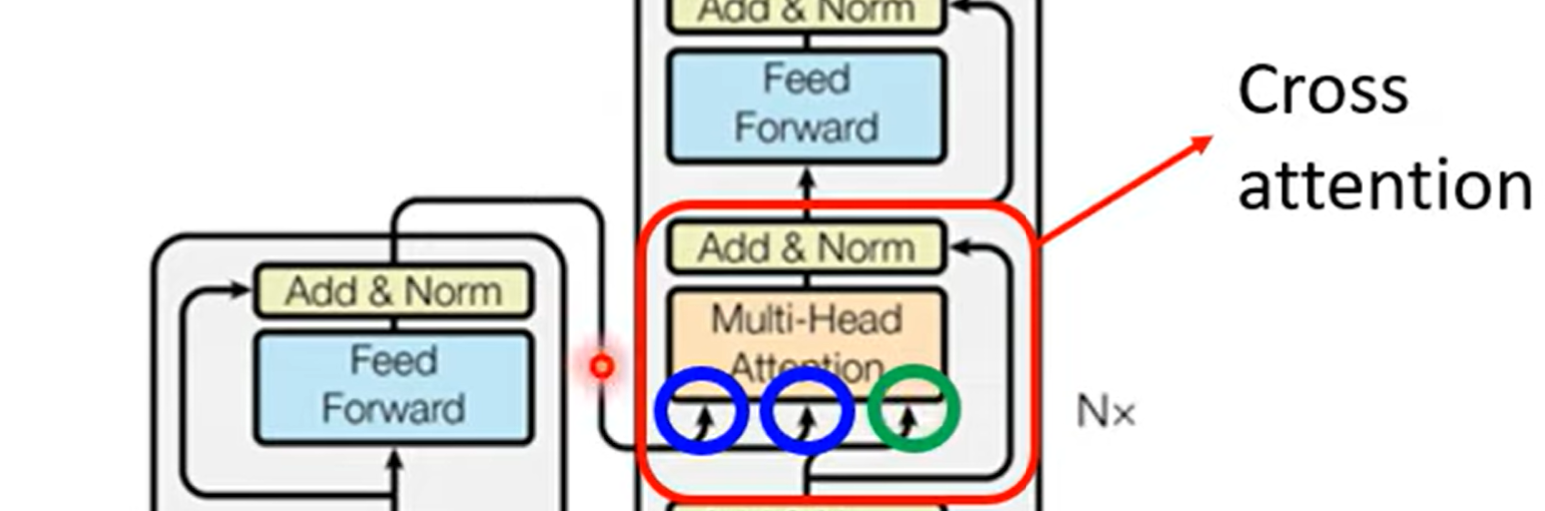
Cross Attention:Decoder 产生的 q,从 Encoder 中提取特征
拓展:不同的 Cross Attention 办法,Rethinking and Improving Natural Language Generation with Layer-Wise Multi-View Decoding
模型训练
目的:Minimize cross entropy(注意,最后还会输出 END 的 one-hot vector)
Teacher Forcing:using the ground truth as input
给定“机器学”,就应该输出“习”;
给定“机器学习”,就应该输出“END”。
但在真正用的时候,显然 Decoder 看到的是自己的输入,而非 ground truth 的输入,中间存在 Mimatch
Copy Mechanism:从输入中复制一些东西输出
输入:你好,我是 Hewkick。
输出:Hewkick 你好,很高兴认识你。
显然模型不好理解 Hewkick 是什么,但知道是名字,复制到输出中,就足够了。
应用于摘要之中 - Pointer Network - Get To The Point: Summarization with Pointer-Generator Networks
Guided Attention:要求机器有固定的方式
- 例如在语音合成中,强行让机器从左到右去 Attention。
Beam Search:不搞纯粹贪心算法
暴力搜索肯定不行;
Beam Search 即可,但有时候有用,有时候没用。需要根据任务来看。
没用的例子,对于有一定创造力的任务(如续写文章),找出分数最高的路不一定好,The Curious Case of Neural Text Degeneration
评估方法用什么?
我们用 Cross Entropy 训练(希望最小化),却用 BLEU score 去评估(希望最大化);
使用 BLEU score 去训练?有些难;
强化学习硬 Train 一发:When you don’t know how to optimize, just use reinforcement learning (RL)! Flow-based network analysis of the Caenorhabditis elegans connectome
Scheduled Sampling:在训练的时候给 Decoder 一些错误的东西,反而可以让 Decoder 训练得更好!
但是会伤害到 Transformer 平行化的能力;
Original Scheduled Sampling, Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks
Scheduled Sampling for Transformer, Scheduled Sampling for Transformers
Parallel Scheduled Sampling, Parallel Scheduled Sampling