【大模型】微调学习
之后整理
【大模型】微调学习
微调办法
Hard Prompt:离散Prompt,是一个实际的文本字符串(自然语言,人工可读),通常由中英文词汇组成Soft Prompt:连续Prompt,通常是在向量空间优化出来的提示,通过梯度搜索之类的方式进行优化
全量微调
1
- 开销大,参数全改
Freeze微调
1
- 简单微调,在数据集较小的情况下可以起到比较好的作用
Prefix-Tuning
1
2
3
4
5
只更新`Prefix`部分的参数,而其它部分参数固定。显然`Prefix-Tuning`属于`Soft Prompt`
- `Encoder`端增加前缀是为了引导输入部分的编码,`Decoder`端增加前缀是为了引导后续`token`的生成
- [论文地址](https://arxiv.org/abs/2101.00190)
Prompt Tuning
1
2
3
4
5
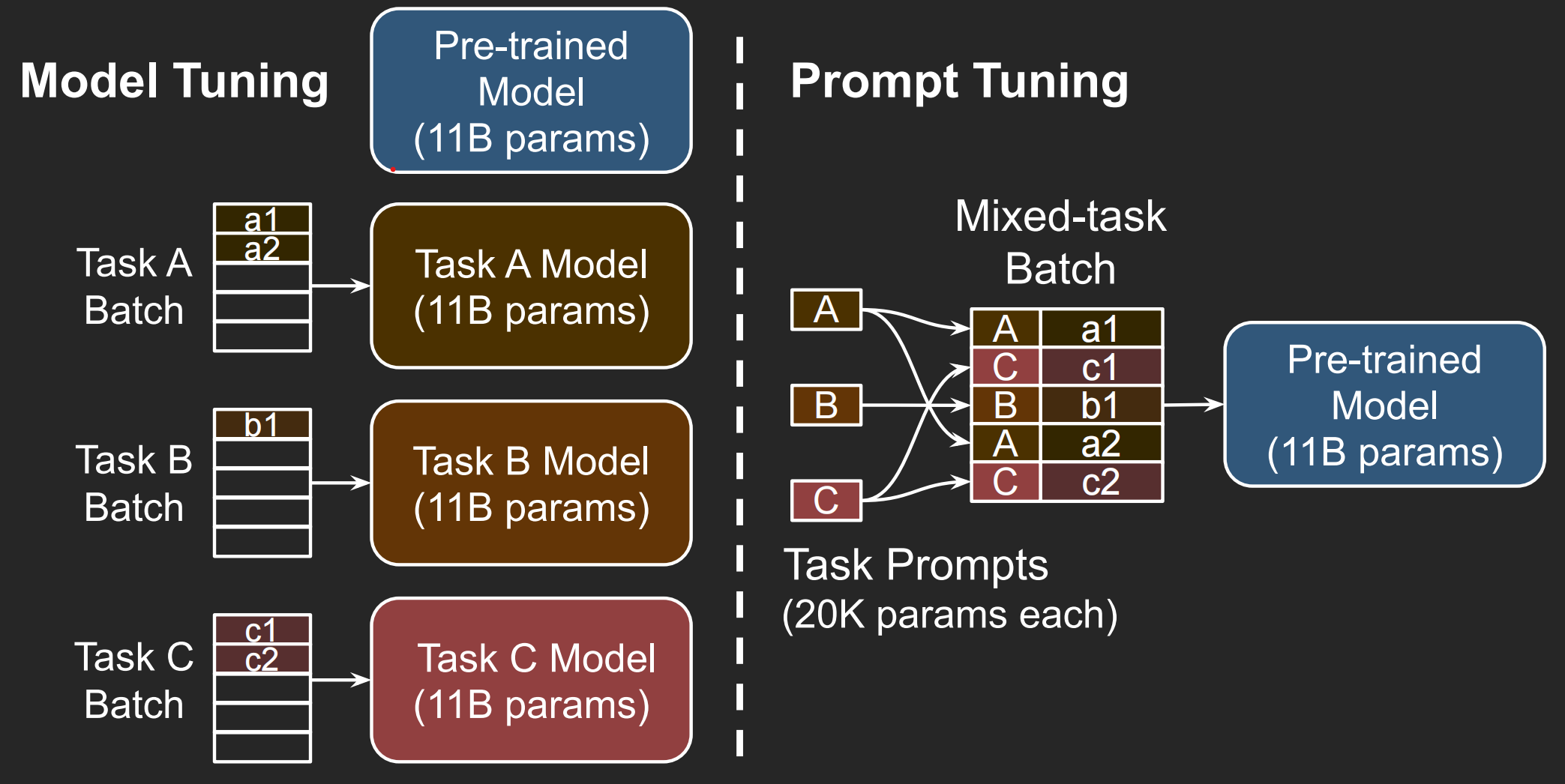
`Prompt Tuning`可以看作是`Prefix Tuning`的简化版本,更适用于多任务微调
存在一个`Mixed-task Batch`,跟`Model Tuning`不一样,如图:
- [论文地址](https://arxiv.org/abs/2104.08691)
P-Tuning v1
1
2
3
加入隐式的`virtual token`,只对其进行更新,而不更新大模型中的参数
- [论文地址](https://arxiv.org/abs/2103.10385)
P-Tuning v2
1
2
3
4
5
原有的微调办法不完全适合小参数模型,故有了改进办法:
基于`P-Tuning`与`Prefix-Tuning`,在每一层都加入一个提示。这增加了可以学习的参数数量;同时,该微调办法有助于多任务处理
- [论文地址](https://arxiv.org/abs/2110.07602)
LoRA
1
2
3
- LoRA微调适用于数据量较小、计算资源有限的场景
- [论文地址](https://arxiv.org/abs/2106.09685)
QLoRA
1
- 后面写
This post is licensed under CC BY 4.0 by the author.