CMU机器学习“大神”:音乐是计算出来的?!
AI如何颠覆音乐界——挑战和应用
注意这是 2017 年的课程
AI + Music listening (Content-based MIR)
Music Fingerprint 音乐指纹
i.i.d 或 Non-i.i.d “Independent and Identically Distributed” 的缩写,“独立同分布”。
通过概率论知识,可转化为正态分布,可证明该 MIR 算法的鲁棒性
提升 MIR 能力
Shazam:设置 strong / wear bits
Google:等到算法仅提供一个足够自信的答案
问题在于:该 MIR 算法针对 exact match,那对于一首乐曲的不同版本,该如何对比?
Query by Humming 哼唱检索
基于旋律的检索:正常人一般都哼主旋律,而不是哼和弦和贝斯(笑
部分检索、模糊搜索、跑调/速度不同等问题
理想化解决办法
不妨先假设人不跑调(理想化输入),转化为 MIDI 文件(类似于字符串文件)
音高判读:YIN algorithm
时长判断:Onset detection
不妨使用动态规划 dp 算法
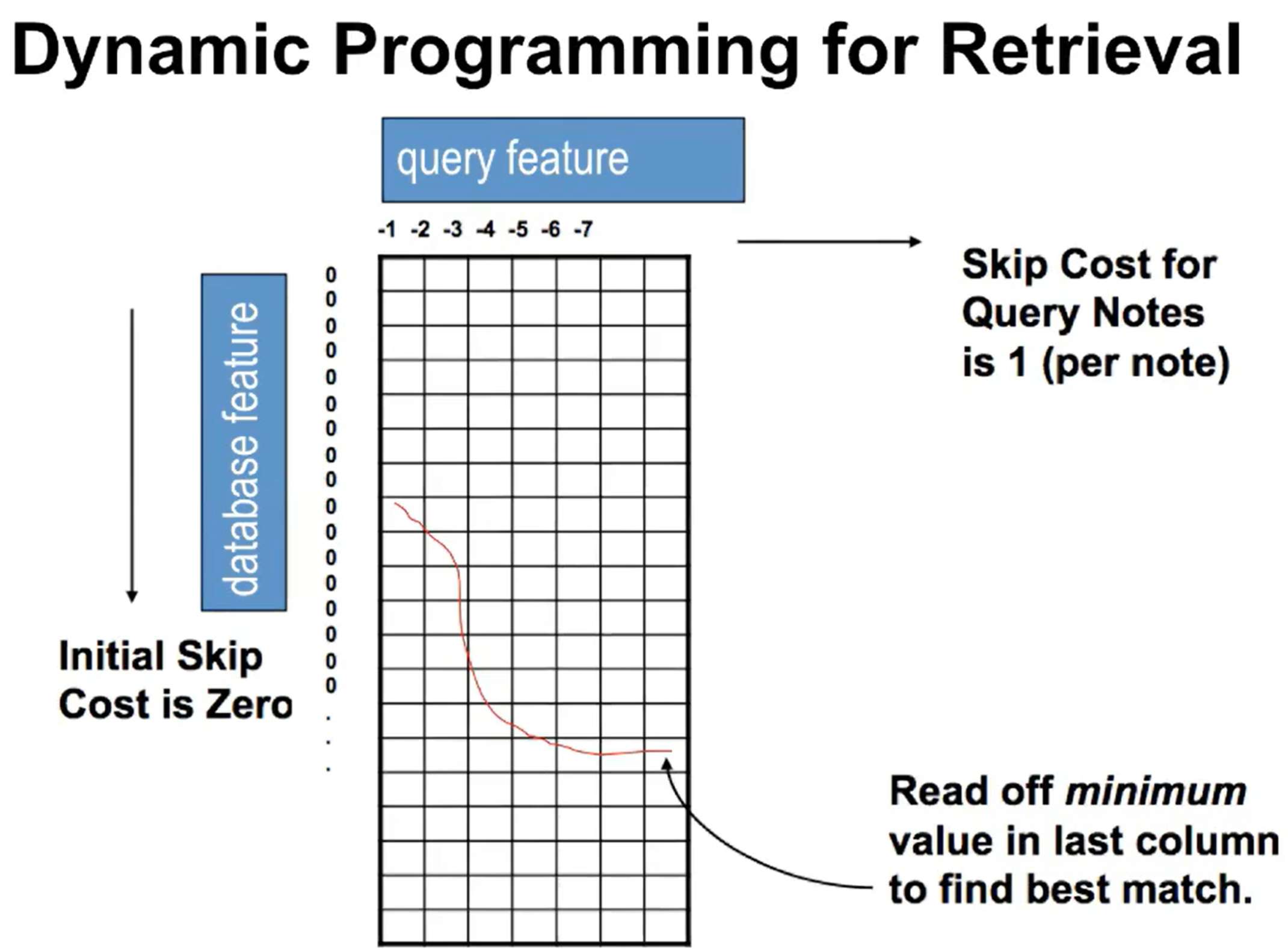
真实世界下解决办法
Frist-step filtering(先粗筛)
Pitch histogram:画出音高包络,进行对比,筛掉差的太远的
Pitch contour:检查上行还是下行
duration contour:检查时长
Human editing(人工预处理)
Parse the theme:只保留副歌
Weight the popularity:流行度权重
Genre / style classification 曲风分类
ML 办法:Pattern Recognition,取类比象,提取特征,放到多分类器中
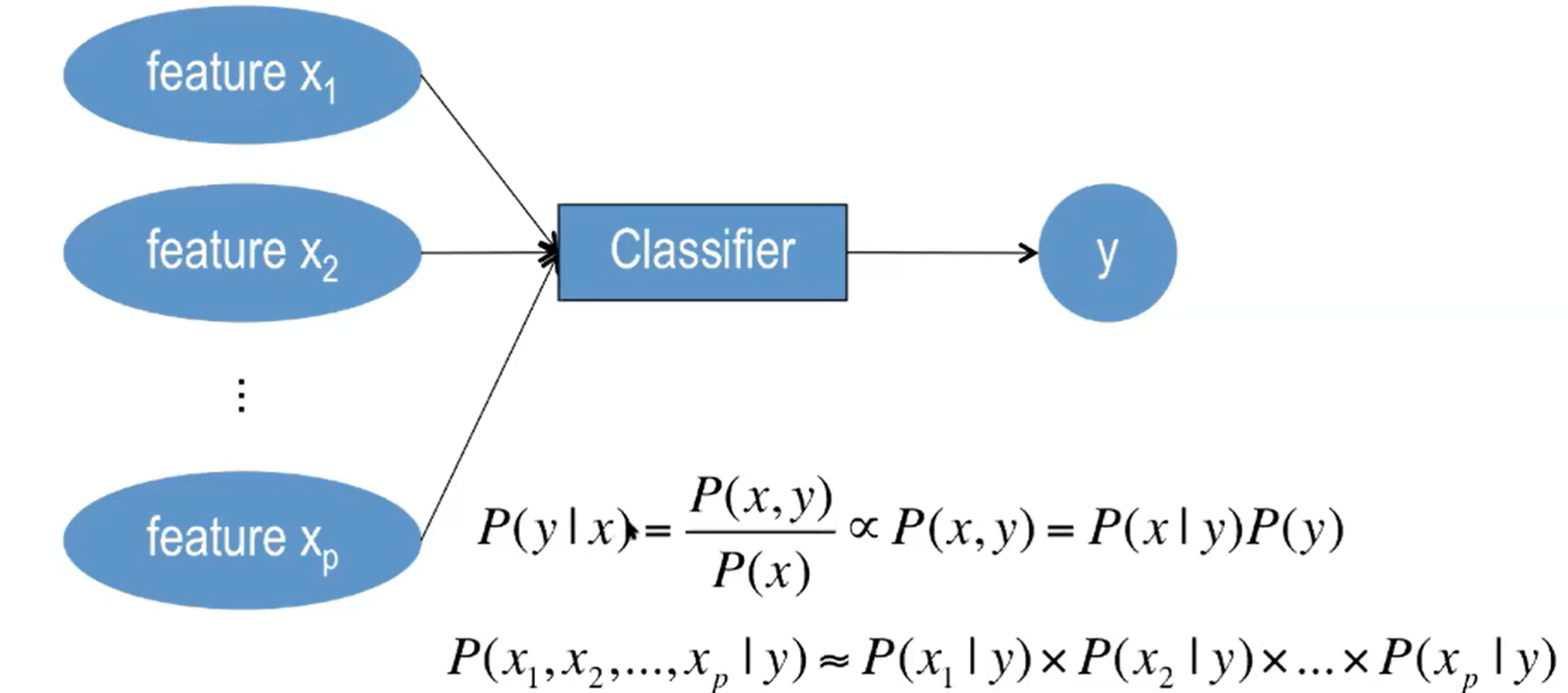
Features 特征
Chroma 色彩:相比于 frequency,chroma 可以获取语义信息(音高 C D E F…)
Beat Detection / Tempo Estimation 节拍速度:
难做,因为有的古典乐曲没有明确速度;现代舞曲还算好做;
怎么做:先提取出来 feature,做一个自相关函数 Auto-correlative function,找突出(重拍)位置
AI + Music Composition
1000 年前,有 Guido D’Arezzo 研发出基于 look-up table(查找表)的作曲算法,既然音乐能转化为文本,那么文本也能转化为音乐;
Canon(卡农):同一段旋律的平移与重叠;
接下来介绍四种算法,四种算法并非互相排斥
Deterministic algorithm 决定性算法
- 一行代码即可!尝试一下?
1
t & t >> 8
- Sierpinski’s Triangle 分形三角形

Stochastic process 随机性算法
一行代码:古典概型,但显然这种随机产生的旋律没有记忆性;
Markov:这样子就有记忆了
ML in music
把音乐看作序列,按照训练文本序列的方式训练产出音乐
Google deepmind - WaveNet
像 DNA 一样打碎,再 recombination
Mapping Phenomena to Music 映射至音乐
从图片映射至音乐,设置 RGB 各自映射到什么元素
将 sorting algorithm 映射到音乐(网上看到的抽象排序小视频,边排序边出声的)
AI + Music performance
- 不妨把演奏乐器的过程看作是调用函数的过程
改变发声体:计算机声音合成
录音:弹一下,就把对应的音播放出来
通过波形合成出来想要的音
FM(频率调制)合成
改变控制芯片
用香蕉也可以制作音乐
实体界面变成虚拟界面
改变函数调用
rule-based system: analysis by synthesis
钢琴 solo - ML: learn P(performance score); Note -> Phrase
乐谱跟随
一个人弹复调乐曲的 A 声部,机器可以做到跟随着发出 B 声部的声音
但是需要音准,并且人声并不是一板一眼地唱
Soft matching

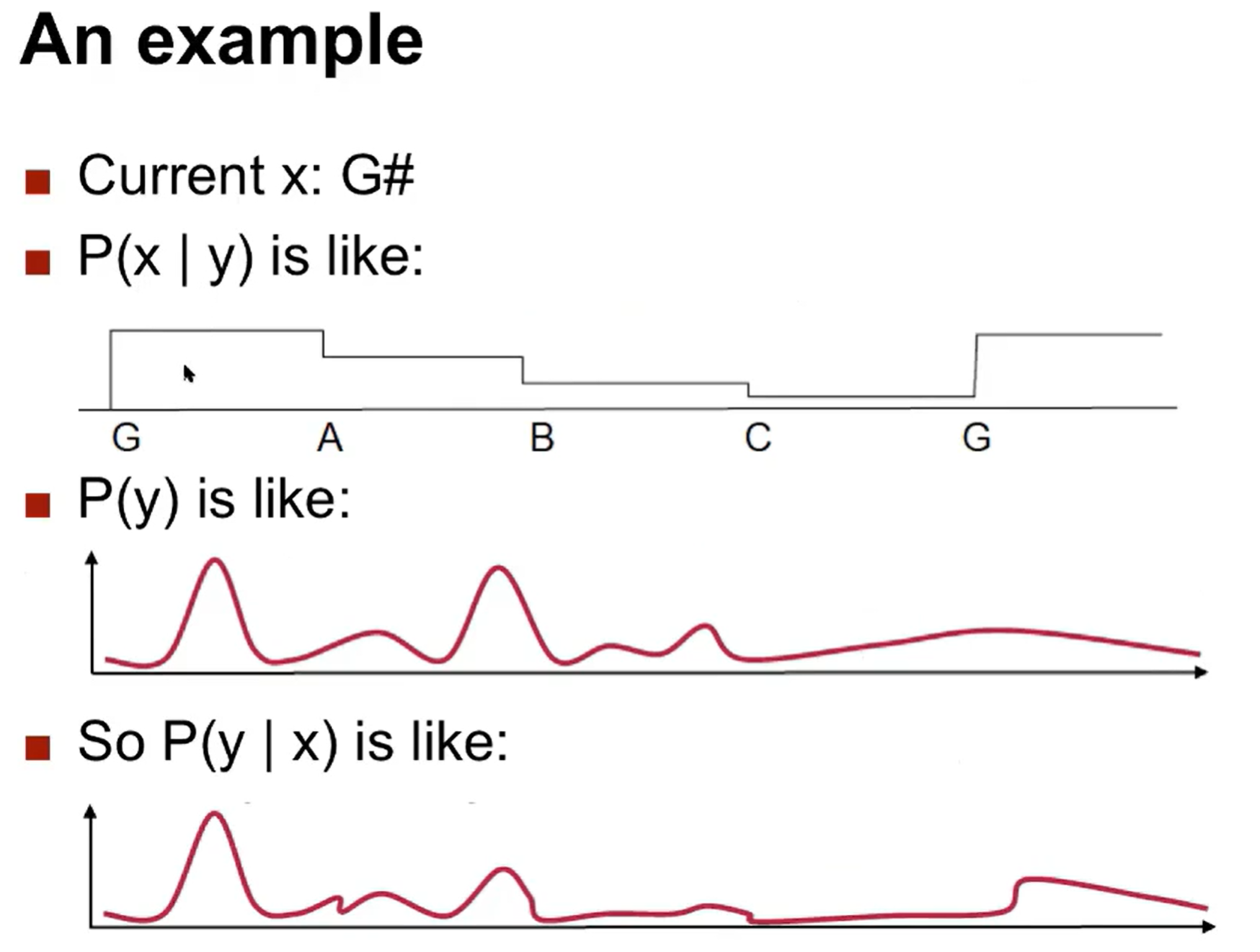
Beat tracking
没有乐谱?我们就跟随节奏!
使用 ML 学习几次彩排中,人是如何渐快渐慢的 - 数据量太小,使用 DL 数据量不够
Future
- 2017 年的展望
Motion record
- 期望记录弹乐器时的动作,并且可以泛化到各种场景中(家中和演奏厅演奏,声响效果不同)
Style record
- 学习特定演奏家的风格
使用机器教人
- 从机器学习到人学习